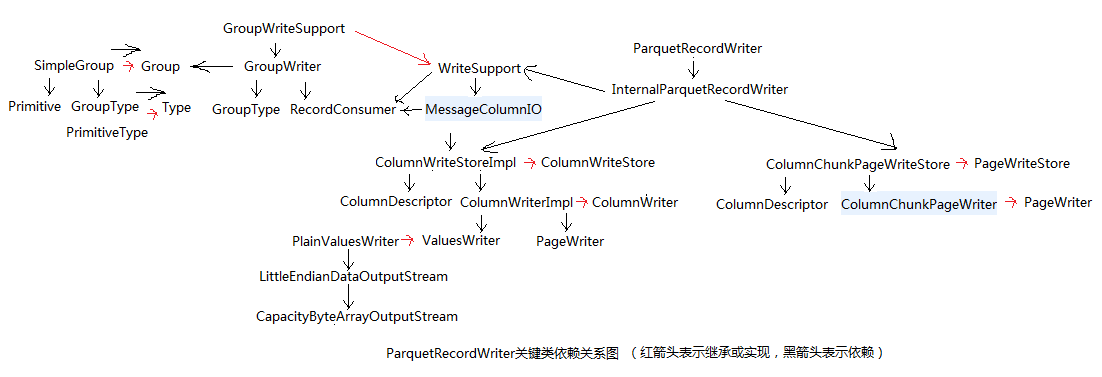
1、parquet文件结构相关类
ParquetMetadata
ParquetMetaData类封装了Parquet文件的元数据信息,其包含一个FileMetaData类和一个BlockMetaData List,并且提供静态方法,采用org.codehaus.jackson包将ParquetMetaData变成json格式,当然也提供函数将json格式的元数据转换成一个ParquetMetaData对象。
1 | public class ParquetMetadata { |
FileMetaData
FileMetaData类包含文件的元数据,包含数据描述信息schema、String键值对Map<String,String>、以及文件创建版本信息。
1 | public final class FileMetaData implements Serializable { |
keyValueMetaData中一般会存储parquet的补充信息,不同软件生成的信息不同:
- sparksql生成的信息如下:
1 | { |
- sqoop生成的如下:
1 | { |
BlockMetaData
row group元数据
1 | public class BlockMetaData { |
MessageType
MessageType 是 GroupType 的子类,代表Parquet描述数据字段的schema的根节点
1 | public final class MessageType extends GroupType { |
2、数据类型相关类
Type
抽象类Type封装了当前字段的名称、重复类型(Repetition)、以及逻辑类型(OriginalType)。
其中OriginalType中对应关系:
| MAP | LIST | UTF8 | MAP_KEY_VALUE | ENUM | DECIMAL |
|---|---|---|---|---|---|
| 哈希映射表Map | 线性表List | UTF8编码的字符串 | 包含键值对的Map | 枚举类型 | 十进制数 |
1 | public abstract class Type { |
Type 有两个子类PrimitiveType和GroupType,分别代表Parquet支持的原始数据类型和Group多个字段的组合类型。
GroupType
多个字段的组合类型
1 | public class GroupType extends Type { |
PrimitiveType
Parquet支持的原始数据类型
1 | public final class PrimitiveType extends Type { |
3、Group相关
Group
抽象类Group表示包含一组字段的Parquet schema节点类型,封装了各种类型的 add方法和get方法
SimpleGroup
SimpleGroup是Group的一个子类,一个最简单形式的Group:包含一个GroupType 和字段数据。
GroupType表示Group类型。
List<Object>[] data保存该Group中的字段数据,各字段在List数组中的顺序和GroupType中定义的一致。List列表中既可以保存Primitive类型的原始数据类型,也可以保存一个Group。也就是说一个SimpleGroup类型可以表示由schema表示的一行记录。
1 | public class SimpleGroup extends Group { |