Connection conn = getNonManagedTXConnection(); try { // Other than the first time, always checkin first to make sure there is // work to be done before we acquire the lock (since that is expensive, // and is almost never necessary). This must be done in a separate // transaction to prevent a deadlock under recovery conditions. List<SchedulerStateRecord> failedRecords = null; if (!firstCheckIn) { failedRecords = clusterCheckIn(conn); commitConnection(conn); } if (firstCheckIn || (failedRecords.size() > 0)) { getLockHandler().obtainLock(conn, LOCK_STATE_ACCESS); transStateOwner = true; // Now that we own the lock, make sure we still have work to do. // The first time through, we also need to make sure we update/create our state record failedRecords = (firstCheckIn) ? clusterCheckIn(conn) : findFailedInstances(conn); if (failedRecords.size() > 0) { getLockHandler().obtainLock(conn, LOCK_TRIGGER_ACCESS); //getLockHandler().obtainLock(conn, LOCK_JOB_ACCESS); transOwner = true; clusterRecover(conn, failedRecords); recovered = true; } } commitConnection(conn); } catch (JobPersistenceException e) { rollbackConnection(conn); throw e; } finally { try { releaseLock(LOCK_TRIGGER_ACCESS, transOwner); } finally { try { releaseLock(LOCK_STATE_ACCESS, transStateOwner); } finally { cleanupConnection(conn); } } }
protected List<SchedulerStateRecord> findFailedInstances(Connection conn) throws JobPersistenceException { try { List<SchedulerStateRecord> failedInstances = new LinkedList<SchedulerStateRecord>(); boolean foundThisScheduler = false; long timeNow = System.currentTimeMillis(); // 获取 qrzt_scheduler_state 表中,记录。对应sql是:SELECT * FROM QRTZ_SCHEDULER_STATE WHERE SCHED_NAME = 'zl',其中SCHED_NAME是配置文件中的org.quartz.scheduler.instanceName值 List<SchedulerStateRecord> states = getDelegate().selectSchedulerStateRecords(conn, null);
for(SchedulerStateRecord rec: states) { // find own record... if (rec.getSchedulerInstanceId().equals(getInstanceId())) { foundThisScheduler = true; if (firstCheckIn) { failedInstances.add(rec); } } else { // find failed instances... if (calcFailedIfAfter(rec) < timeNow) { failedInstances.add(rec); } } } // The first time through, also check for orphaned fired triggers. if (firstCheckIn) { failedInstances.addAll(findOrphanedFailedInstances(conn, states)); } // If not the first time but we didn't find our own instance, then // Someone must have done recovery for us. // !foundThisScheduler 表示 应用程序没有找到 自己的 instance // !firstCheckIn 表示 应该表示 应用程序是否为第一次checkIn if ((!foundThisScheduler) && (!firstCheckIn)) { // FUTURE_TODO: revisit when handle self-failed-out impl'ed (see FUTURE_TODO in clusterCheckIn() below) getLog().warn( "This scheduler instance (" + getInstanceId() + ") is still " + "active but was recovered by another instance in the cluster. " + "This may cause inconsistent behavior."); } return failedInstances; } catch (Exception e) { lastCheckin = System.currentTimeMillis(); thrownew JobPersistenceException("Failure identifying failed instances when checking-in: " + e.getMessage(), e); } }
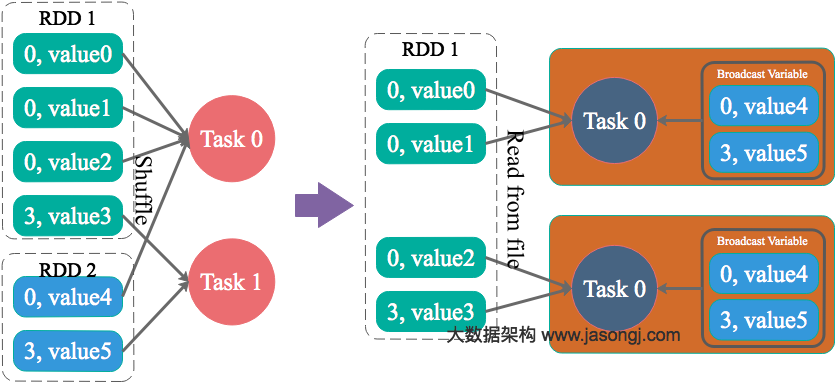
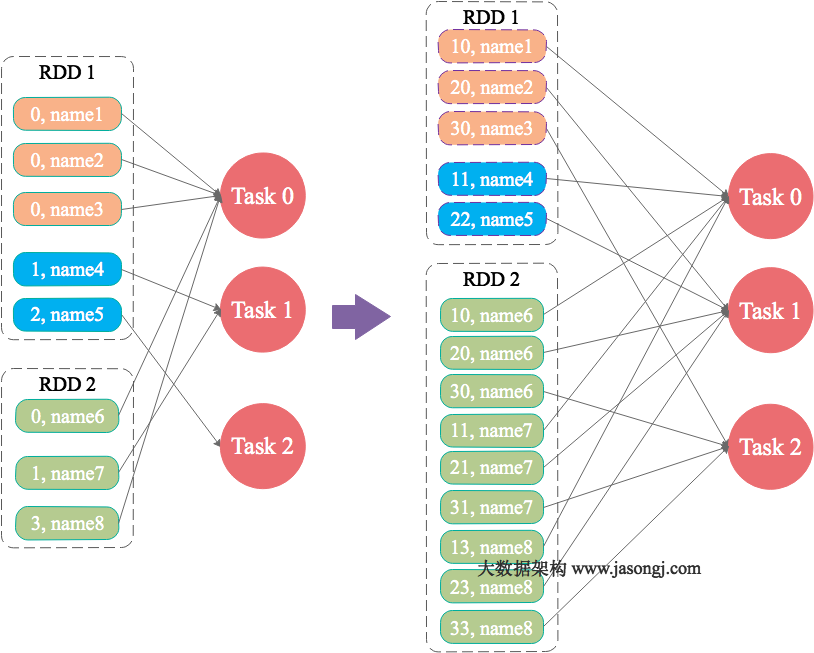
val input = sc.parallelize(1 to 10) val repartitioned = input.repartition(2) val sum = repartitioned.sum
我们就可以通过在RDD上调用toDebugString来查看其依赖以及转化关系,结果如下:
1 2 3 4 5 6 7 8 9 10
// input.toDebugString res0: String = (4) ParallelCollectionRDD[0] at parallelize at <console>:21 []
// repartitioned.toDebugString res1: String = (2) MapPartitionsRDD[4] at repartition at <console>:23 [] | CoalescedRDD[3] at repartition at <console>:23 [] | ShuffledRDD[2] at repartition at <console>:23 [] +-(4) MapPartitionsRDD[1] at repartition at <console>:23 [] | ParallelCollectionRDD[0] at parallelize at <console>:21 []
overrideprotecteddeftrain(dataset: Dataset[_]): GBTClassificationModel = { val categoricalFeatures: Map[Int, Int] = MetadataUtils.getCategoricalFeatures(dataset.schema($(featuresCol))) val oldDataset: RDD[LabeledPoint] = dataset.select(col($(labelCol)), col($(featuresCol))).rdd.map { caseRow(label: Double, features: Vector) => require(label == 0 || label == 1, s"GBTClassifier was given" + s" dataset with invalid label $label. Labels must be in {0,1}; note that" + s" GBTClassifier currently only supports binary classification.") LabeledPoint(label, features) } val numFeatures = oldDataset.first().features.size val boostingStrategy = super.getOldBoostingStrategy(categoricalFeatures, OldAlgo.Classification)
val instr = Instrumentation.create(this, oldDataset) instr.logParams(params: _*) instr.logNumFeatures(numFeatures) instr.logNumClasses(2)
val (baseLearners, learnerWeights) = GradientBoostedTrees.run(oldDataset, boostingStrategy, $(seed)) val m = newGBTClassificationModel(uid, baseLearners, learnerWeights, numFeatures) instr.logSuccess(m) m }
overrideprotecteddefpredict(features: Vector): Double = { // TODO: When we add a generic Boosting class, handle transform there? SPARK-7129 // Classifies by thresholding sum of weighted tree predictions val treePredictions = _trees.map(_.rootNode.predictImpl(features).prediction) val prediction = blas.ddot(numTrees, treePredictions, 1, _treeWeights, 1) if (prediction > 0.0) 1.0else0.0 }
private[ml] traitHasMaxIterextendsParams{ val maxIter: IntParam = newIntParam(this, "maxIter", "max number of iterations") defgetMaxIter: Int = get(maxIter) }
val scaler = new StandardScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
val lr = new LogisticRegression()
.setFeaturesCol(scaler.getOutputCol)
val pipeline = new Pipeline()
.setStages(Array(scaler, lr))
val model = pipeline.fit(dataset)
val predictions = model.transform(dataset)
.select('label, 'score, 'prediction)
scala> df.printSchema root |-- current_date(): date (nullable = false)
Internally, current_date creates a Column with CurrentDate Catalyst leaf expression.
1 2 3 4 5 6 7 8
val c = current_date() import org.apache.spark.sql.catalyst.expressions.CurrentDate val cd = c.expr.asInstanceOf[CurrentDate] scala> println(cd.prettyName) current_date
// no time and format => current time scala> spark.range(1).select(unix_timestamp as "current_timestamp").show +-----------------+ |current_timestamp| +-----------------+ | 1493362850| +-----------------+
// no format so yyyy-MM-dd HH:mm:ss assumed scala> Seq("2017-01-01 00:00:00").toDF("time").withColumn("unix_timestamp", unix_timestamp($"time")).show +-------------------+--------------+ | time|unix_timestamp| +-------------------+--------------+ |2017-01-01 00:00:00| 1483225200| +-------------------+--------------+
Note: From Introducing Stream Windows in Apache Flink:Tumbling windows group elements of a stream into finite sets where each set corresponds to an interval.Tumbling windows discretize a stream into non-overlapping windows.
1 2
scala> val timeColumn = window('time, "5 seconds") timeColumn: org.apache.spark.sql.Column = timewindow(time, 5000000, 5000000, 0) AS `window`
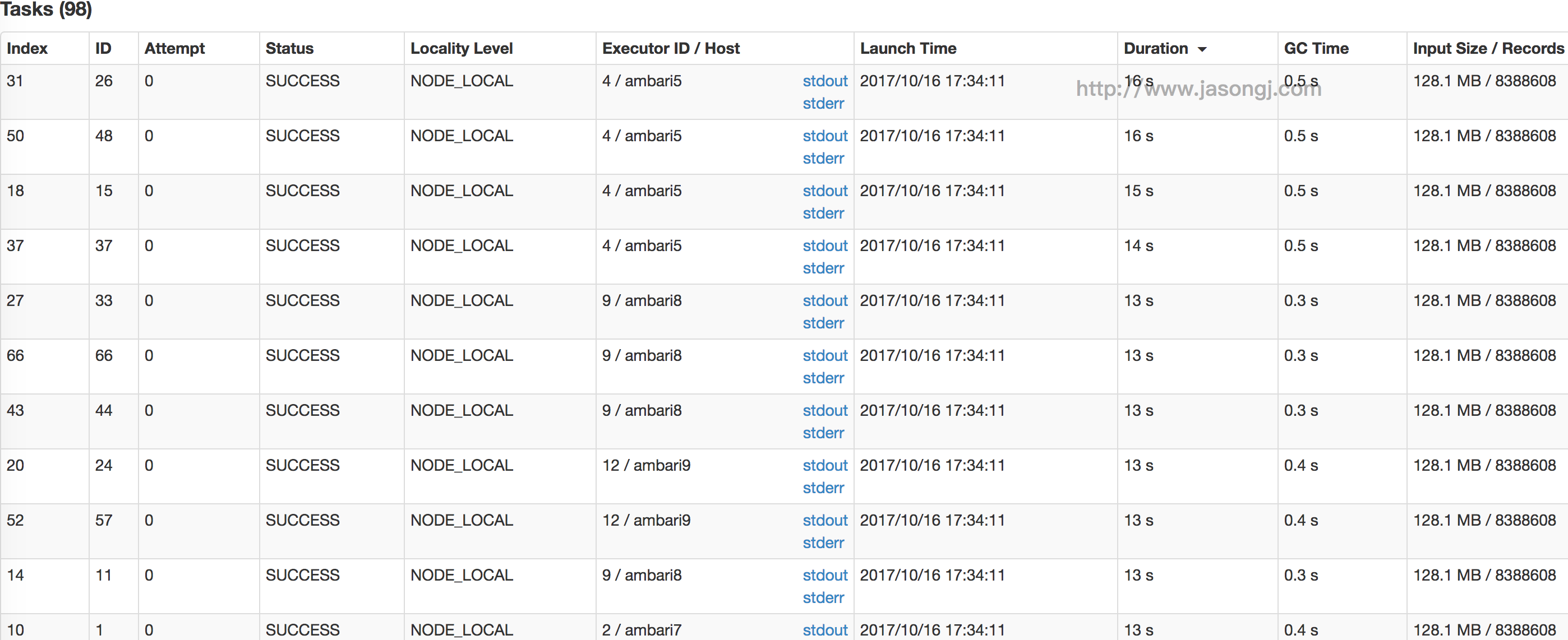
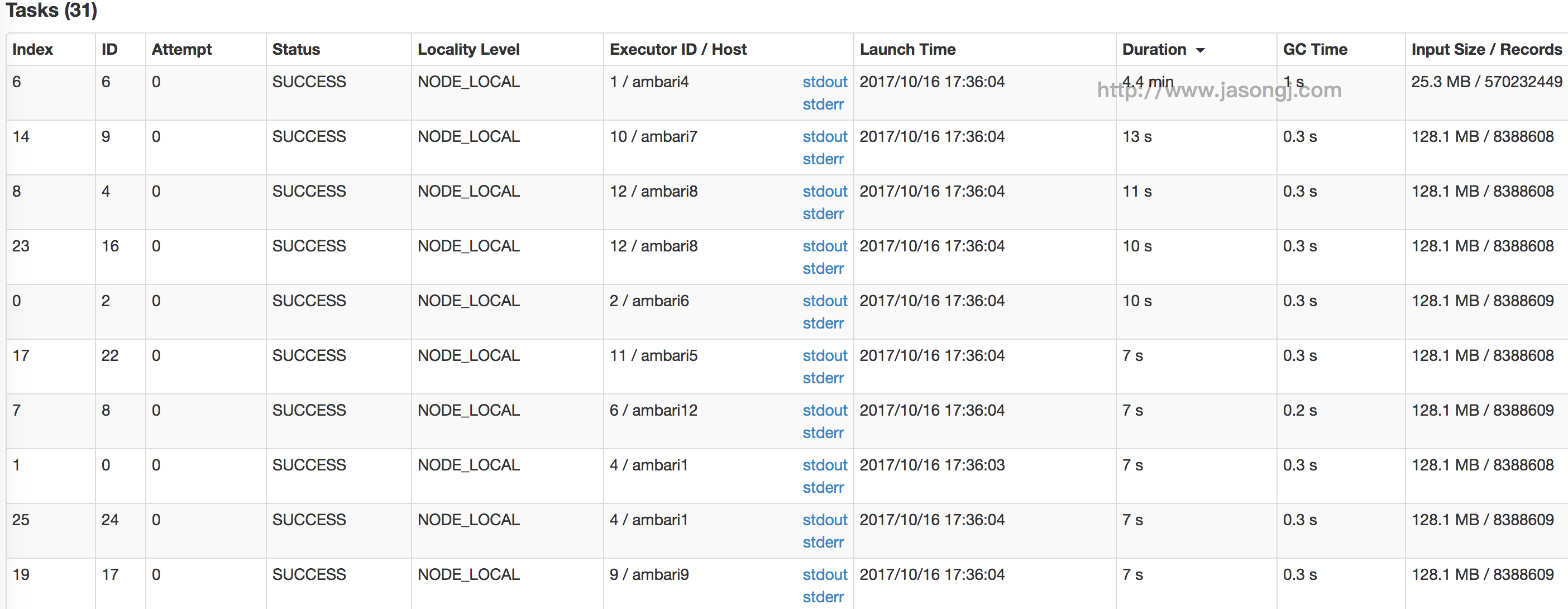
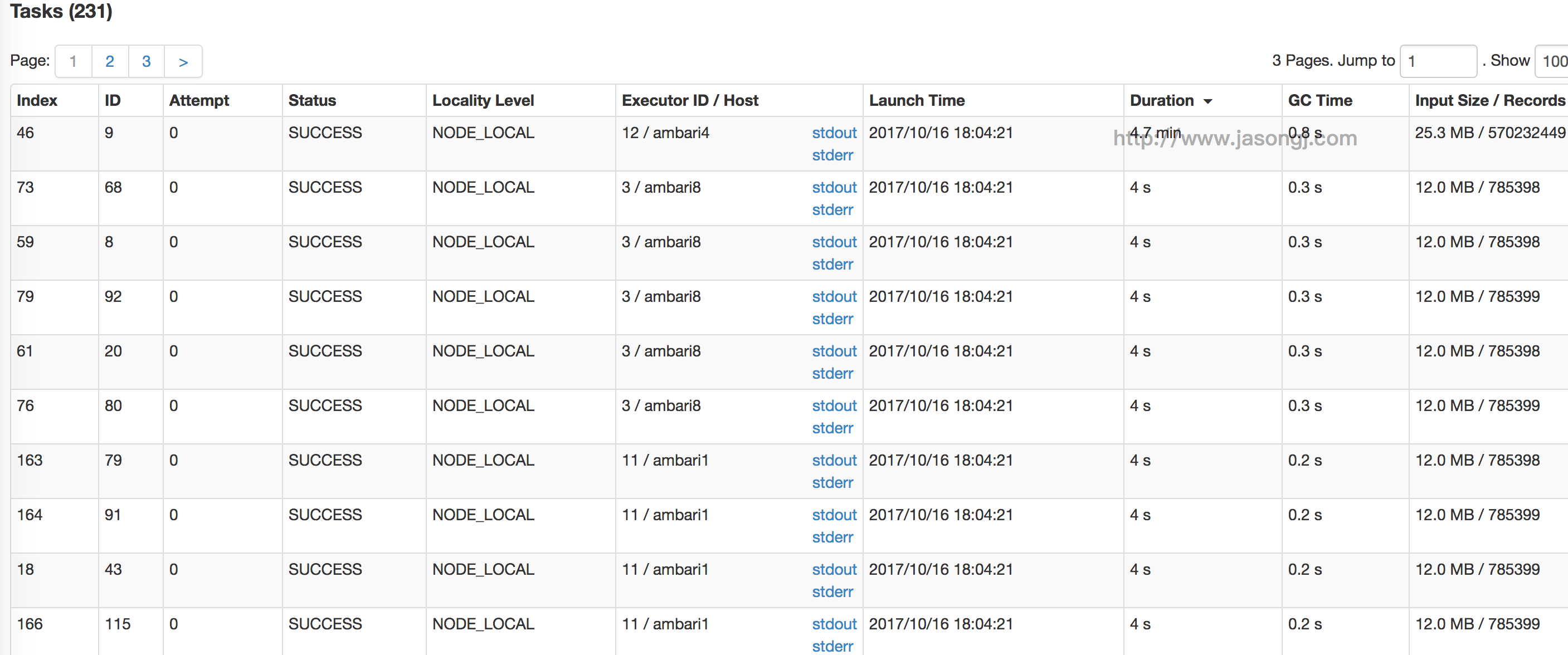
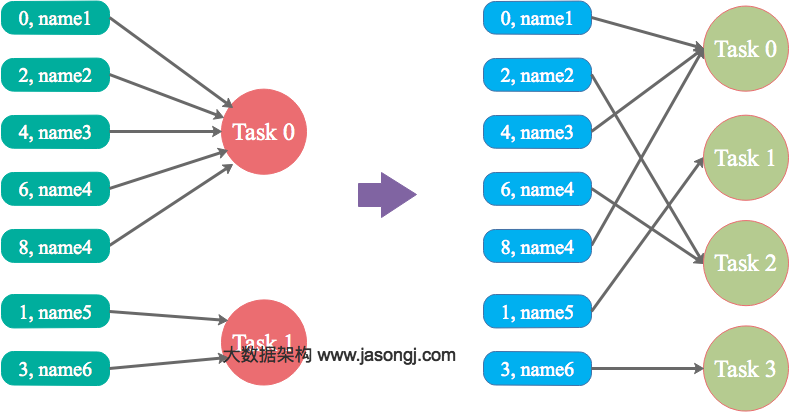
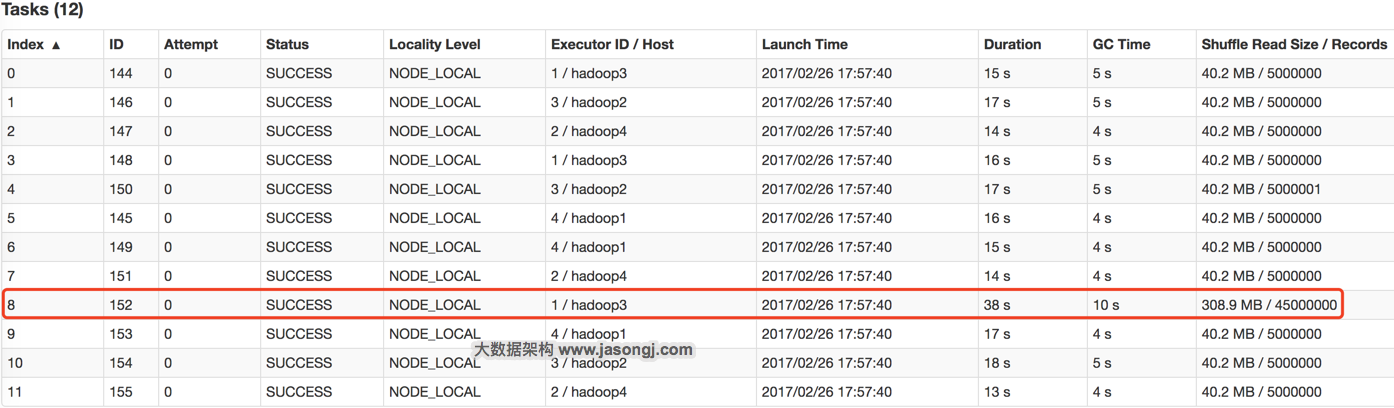
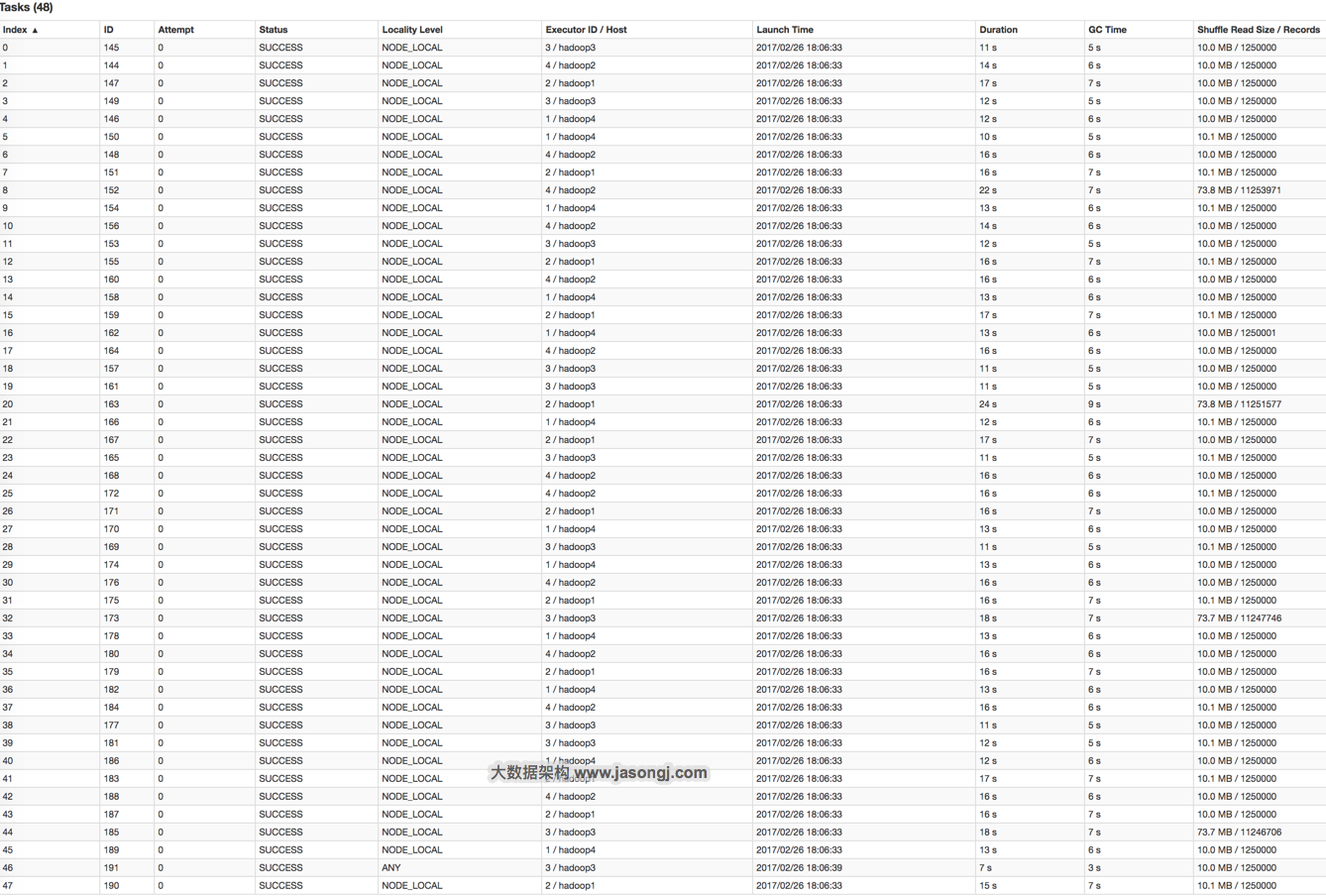
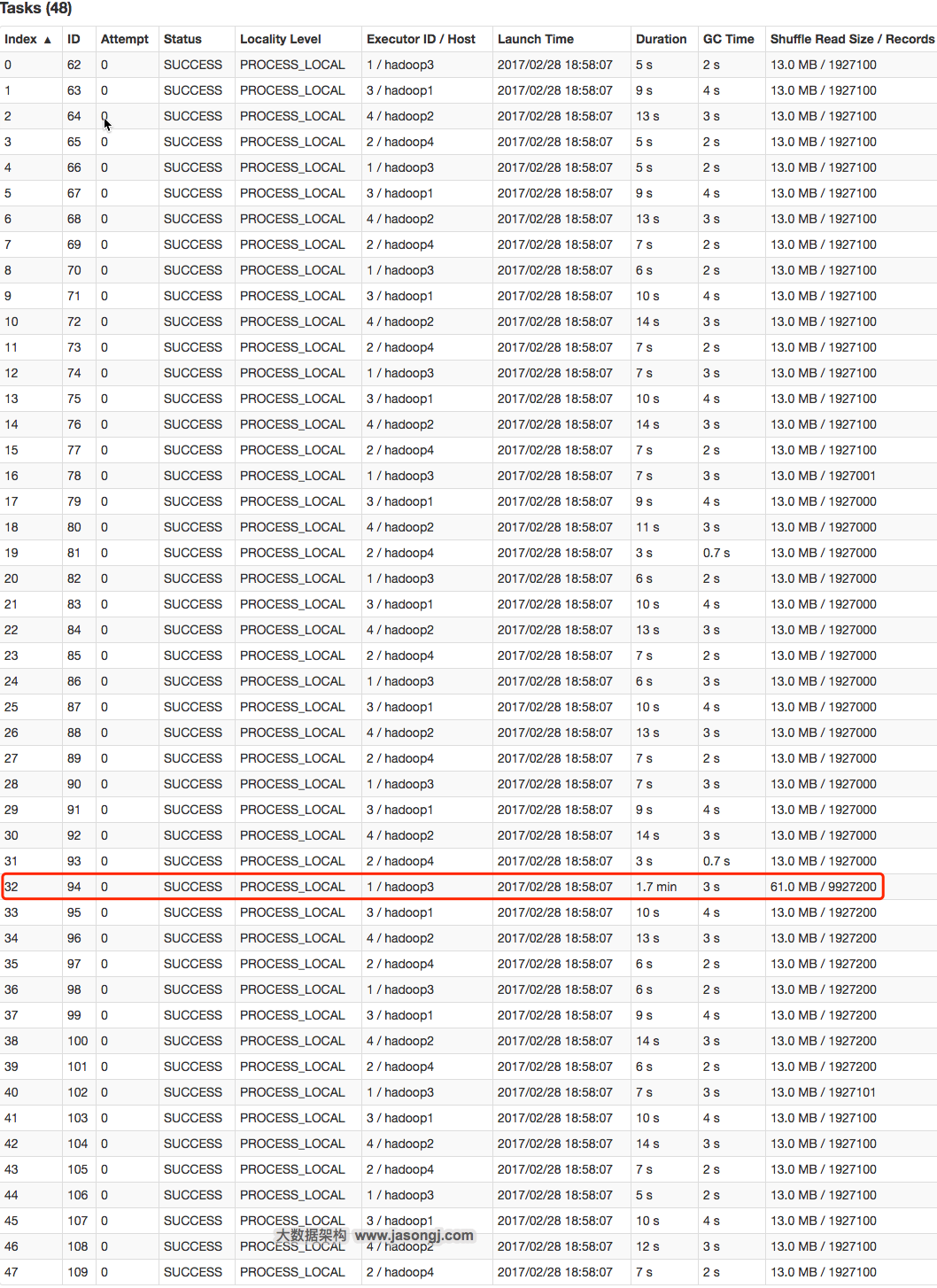
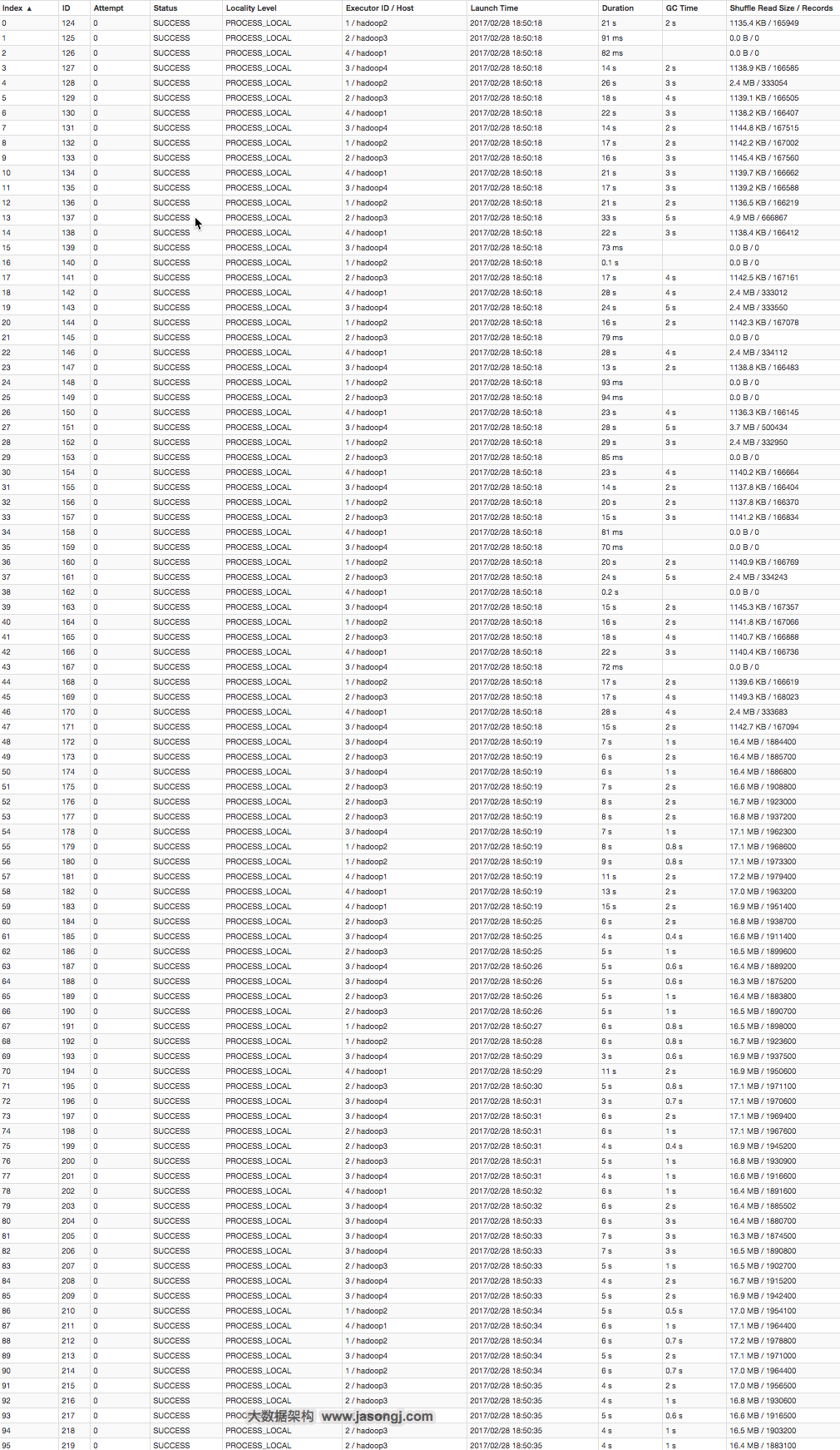
参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
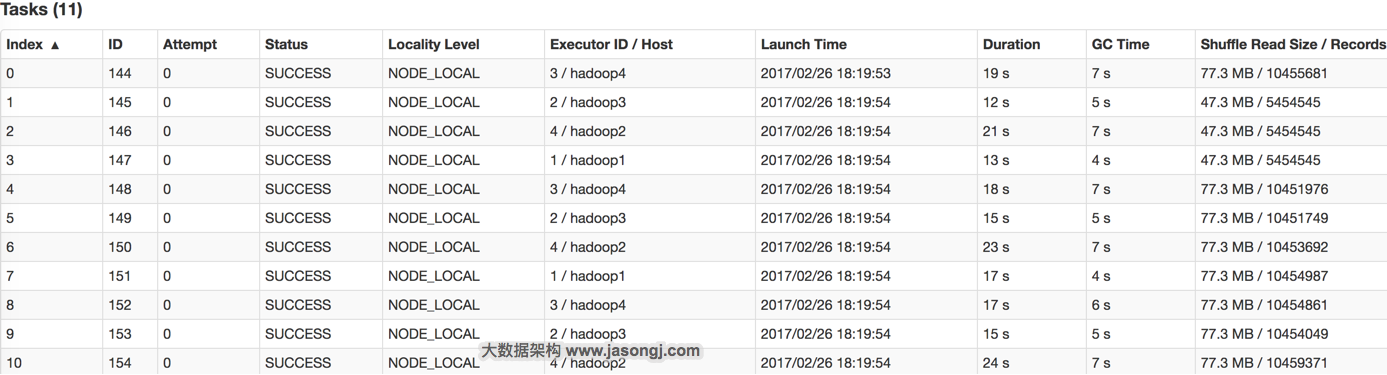
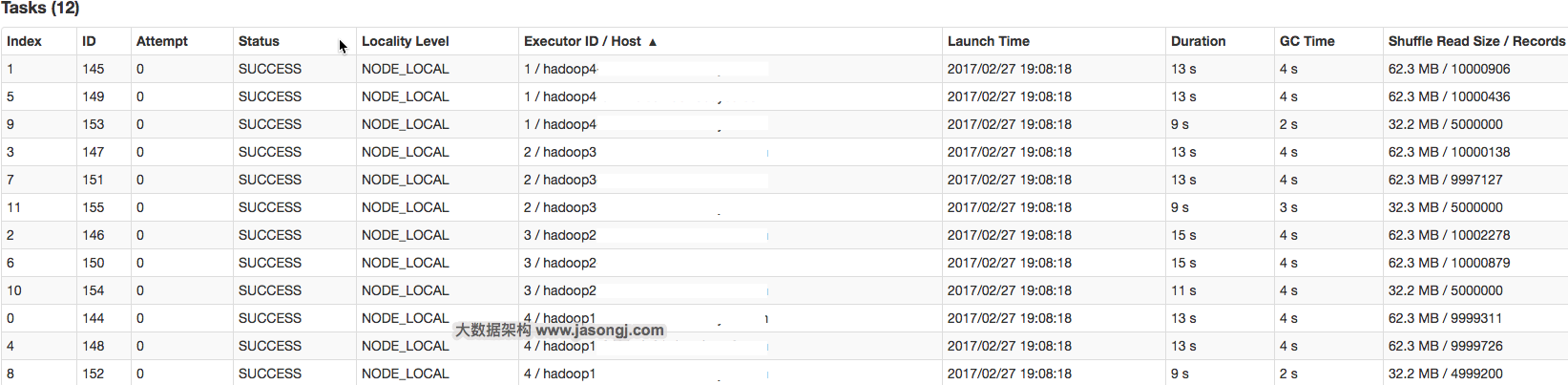
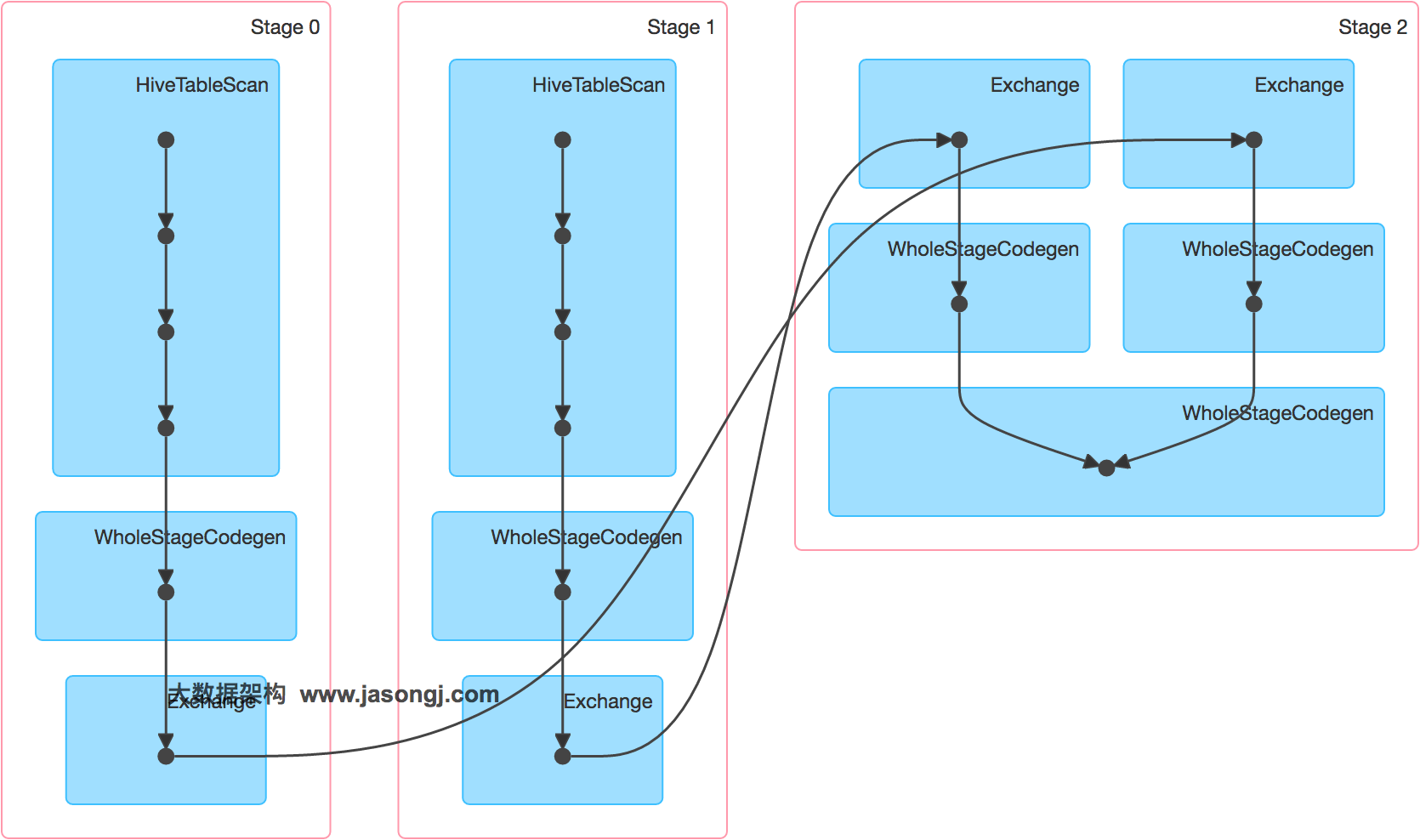
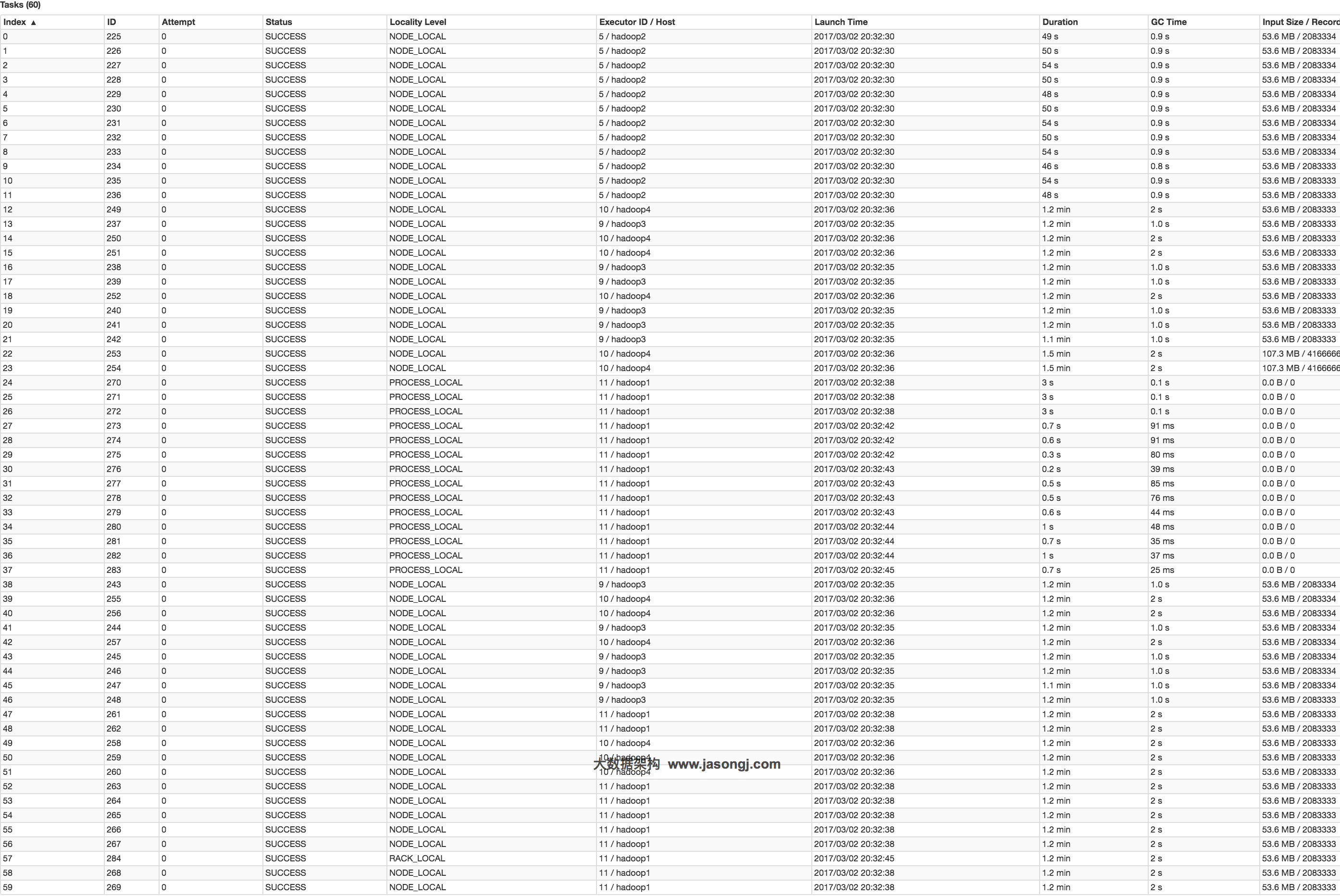
SET spark.sql.autoBroadcastJoinThreshold=104857600; INSERT OVERWRITE TABLE test_join SELECT test_new.id, test_new.name FROM test JOIN test_new ON test.id = test_new.id;
INSERT OVERWRITE TABLE test SELECT CAST(CASE WHEN id < 908000000 THEN (9500000 + (CAST (RAND() * 2 AS INT) + 1) * 48 ) ELSE CAST(id/100 AS INT) END AS STRING), name FROM student_external WHERE id BETWEEN 900000000 AND 1050000000;
INSERT OVERWRITE TABLE test_new SELECT CAST(CAST(id/100 AS INT) AS STRING), name FROM student_delta_external WHERE id BETWEEN 950000000 AND 950500000;
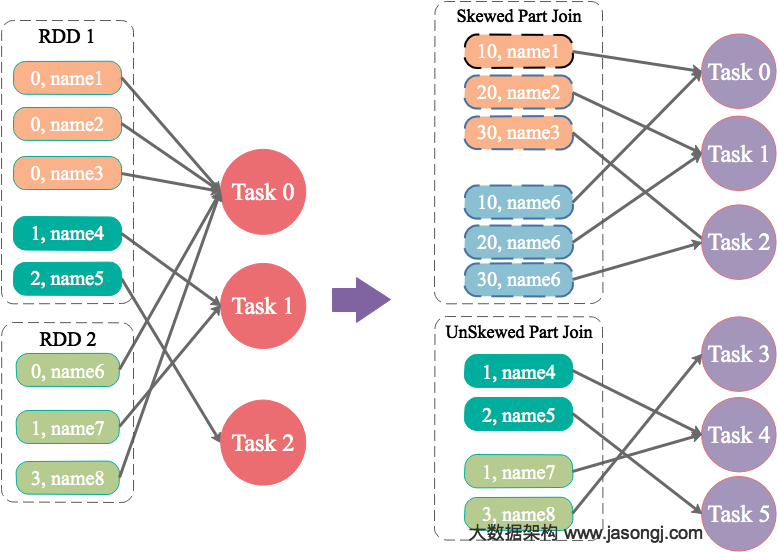
public class SparkDataSkew{ public static void main(String[] args) { SparkConf sparkConf = new SparkConf(); sparkConf.setAppName("DemoSparkDataFrameWithSkewedBigTableDirect"); sparkConf.set("spark.default.parallelism", String.valueOf(parallelism)); JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
public class SparkDataSkew{ public static void main(String[] args) { int parallelism = 48; SparkConf sparkConf = new SparkConf(); sparkConf.setAppName("SolveDataSkewWithRandomPrefix"); sparkConf.set("spark.default.parallelism", parallelism + ""); JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);