1 | package zl.tenant.controller.impl; |
Actuator
SpringBoot四大神器之 Actuator
[TOC]
序
Spring Boot有四大神器,分别是auto-configuration、starters、cli、actuator,本文主要讲actuator。actuator是spring boot提供的对应用系统的自省和监控的集成功能,可以对应用系统进行配置查看、相关功能统计等。
使用actuator
- 添加依赖
1 | <dependency> |
主要暴露的功能
| HTTP方法 | 路径 | 描述 | 鉴权 |
|---|---|---|---|
| GET | /autoconfig | 查看自动配置的使用情况 | true |
| GET | /configprops | 查看配置属性,包括默认配置 | true |
| GET | /beans | 查看bean及其关系列表 | true |
| GET | /dump | 打印线程栈 | true |
| GET | /env | 查看所有环境变量 | true |
| GET | /env/{name} | 查看具体变量值 | true |
| GET | /health | 查看应用健康指标 | false |
| GET | /info | 查看应用信息 | false |
| GET | /mappings | 查看所有url映射 | true |
| GET | /metrics | 查看应用基本指标 | true |
| GET | /metrics/{name} | 查看具体指标 | true |
| POST | /shutdown | 关闭应用 | true |
| GET | /trace | 查看基本追踪信息 | true |
/autoconfig
1 | { |
/configprops
1 | { |
/beans
1 | [ |
/dump
1 | [ |
/env
1 | { |
/health
1 | { |
/info
需要自己在application.properties里头添加信息,比如
1 | info: |
然后请求就可以出来了
1 | { |
/mappings
1 | { |
/metrics
1 | { |
/shutdown
要真正生效,得配置文件开启
1 | endpoints.shutdown.enabled: true |
/trace
记录最近100个请求的信息
1 | [{ |
安全设置
actuator暴露的health接口权限是由两个配置: management.security.enabled 和 endpoints.health.sensitive组合的结果进行返回的。
| management.security.enabled | endpoints.health.sensitive | Unauthenticated | Authenticated (with right role) |
|---|---|---|---|
| false | * | Full content | Full content |
| true | false | Status only | Full content |
| true | true | No content | Full content |
常用配置
1 | management.security.enabled: false # 是否启用安全认证 |
参考资料
SparkContext初始化过程
SparkContext初始化过程
SparkContext是程序执行的入口,一个SparkContext代表一个应用,深入理解spark运行时机制,首先要了解SparkContext初始化过程。
一、SparkContext的定义
1 | //Spark程序的入口 |
构造参数为SparkConf,SparkConf内部用ConcurrentHashMap存储各种配置信息,初始化时会加载所有以spark.开头的环境变量。
1 | // Spark程序的配置信息 |
二、SparkContext初始化
查看初始化对应代码 (位于374行)
克隆和校验SparkConf的变量,接着判断spark.master和spark.app.name是否存在,如果是YARN cluster模式则必须设置spark.yarn.app.id,然后是driver的host,port信息,最后是jars和files,
1 | try { |
_eventLogDir 是否记录运行时信息,由spark.eventLog.enabled和spark.eventLog.dir控制
_eventLogCodec 是否压缩该信息
1 | _eventLogDir = |
如果为yarn-client模式,设置SPARK_YARN_MODE=true
1 | if (master == "yarn" && deployMode == "client") System.setProperty("SPARK_YARN_MODE", "true") |
使用JobProgressListener跟踪运行时信息,用于UI展示,最后创建SparkEnv对象,创建SparkEnv的过程涉及到非常多spark-core中的核心类。
1 | _jobProgressListener = new JobProgressListener(_conf) |
有关UI的信息展示
1 | _statusTracker = new SparkStatusTracker(this) |
读取hadoop配置,将jar和file的路径添加到rpcEnv的fileServer,读取Executor相关变量,重要的参数为ExecutorMemory
1 | _hadoopConfiguration = SparkHadoopUtil.get.newConfiguration(_conf) |
_heartbeatReceiver是默认基于netty实现的心跳机制,创建schedulerBackend用于提交任务,创建taskScheduler和dagScheduler,获取applicationId,启动度量系统,获取eventLogger
1 | _heartbeatReceiver = env.rpcEnv.setupEndpoint( |
executorAllocationManager关于Executor动态资源分配,通过spark.dynamicAllocation.enabled设置,创建contextcleaner用于清理过期的RDD, shuffle和broadcast ,启动ListenerBus,并post环境信息和应用信息,最后添加确保context停止的hook,至此整个sparkcontext的初始化流程结束。
1 | _executorAllocationManager = |
三、总结
通过对sparkcontext初始化过程的跟踪,主要涉及到的内容如下
- SparkConf读取配置和校验,log和UI相关的度量系统。
- 创建SparkEnv,涉及到众多重要对象,如rpcEnv, actorSystem, serializer, closureSerializer, cacheManager, mapOutputTracker, shuffleManager, broadcastManager, blockTransferService, blockManager, securityManager, sparkFilesDir, metricsSystem, memoryManager等。
- 心跳机制,taskScheduler和dagScheduler的创建。
spark 提交任务后,Linux中java 进程说明
spark 提交任务后,Linux中java 进程说明
[TOC]
一、简述
当使用 spark 提交任务后,可在hadoop集群中的一台Linux里 使用 ps -ef | grep jdk1.8 可查看到对应的任务进程信息。
注、本例中使用的是单机模式
二、进程分析
1 | hadoop 110334 110332 0 13:40 ? 00:00:00 /bin/bash -c ./jdk-8u161-linux-x64.tar.gz/jdk1.8.0_161/bin/java -server -Xmx1024m -Djava.io.tmpdir=/home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000001/tmp '-XX:MaxPermSize=2048m' '-XX:PermSize=512m' -Dspark.yarn.app.container.log.dir=/home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000001 org.apache.spark.deploy.yarn.ApplicationMaster --class 'org.apache.spark.ml.alogrithm.SmartRules' --jar hdfs://slave131:9000/user/mls_zl/lib2/cmpt/xxxxx-workflow-component-0.3.2-20180320-1101.jar --arg 'hdfs://slave131:9000/user/mls_3.5/proc/1/11/92/submit_SmartRules_37Client.json' --properties-file /home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000001/__spark_conf__/__spark_conf__.properties 1> /home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000001/stdout 2> /home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000001/stderr |
下面逐条解释上面java进程:
2.1 进程一
进程一表示使用bash -c 启动进程二,并将进程二的信息重定向到指定位置。这里直接说重定向命令参数,其他参数见进程二说明
1 | hadoop 110334 110332 0 13:40 ? 00:00:00 /bin/bash -c ./jdk-8u161-linux-x64.tar.gz/jdk1.8.0_161/bin/java -server -Xmx1024m -Djava.io.tmpdir=/home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000001/tmp '-XX:MaxPermSize=2048m' '-XX:PermSize=512m' -Dspark.yarn.app.container.log.dir=/home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000001 org.apache.spark.deploy.yarn.ApplicationMaster --class 'org.apache.spark.ml.alogrithm.SmartRules' --jar hdfs://slave131:9000/user/mls_zl/lib2/cmpt/xxxxx-workflow-component-0.3.2-20180320-1101.jar --arg 'hdfs://slave131:9000/user/mls_3.5/proc/1/11/92/submit_SmartRules_37Client.json' --properties-file /home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000001/__spark_conf__/__spark_conf__.properties 1> /home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000001/stdout 2> /home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000001/stderr |
信息重定向命令
1> /home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000001/stdout
2> /home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000001/stderr
2.2 进程二: ApplicationMaster
1 | hadoop 110891 110334 99 13:40 ? 00:00:34 ./jdk-8u161-linux-x64.tar.gz/jdk1.8.0_161/bin/java -server -Xmx1024m -Djava.io.tmpdir=/home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000001/tmp -XX:MaxPermSize=2048m -XX:PermSize=512m -Dspark.yarn.app.container.log.dir=/home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000001 org.apache.spark.deploy.yarn.ApplicationMaster --class org.apache.spark.ml.alogrithm.SmartRules --jar hdfs://slave131:9000/user/mls_zl/lib2/cmpt/xxxxx-workflow-component-0.3.2-20180320-1101.jar --arg hdfs://slave131:9000/user/mls_3.5/proc/1/11/92/submit_SmartRules_37Client.json --properties-file /home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000001/__spark_conf__/__spark_conf__.properties |
该进程有 进程一 产生,参数配置和一近乎相当
1. ./jdk-8u161-linux-x64.tar.gz/jdk1.8.0_161/bin/java
使用 jdk1.8 运行
2. -server
java 有2种启动方式 client 和 server 启动方式 ,client模式启动比较快,但运行时性能和内存管理效率不如server模式,通常用于客户端应用程序。相反,server模式启动比client慢,但可获得更高的运行性能。
在 windows上,缺省的虚拟机类型为client模式,如果要使用 server模式,就需要在启动虚拟机时加-server参数,以获得更高性能,对服务器端应用,推荐采用server模式,尤其是多个CPU的系统。在 Linux,Solaris上缺省采用server模式。
3. -Xmx1024m
设置虚拟机内存堆的最大可用大小
4. -Djava.io.tmpdir
设置java 临时目录 为 /home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000001/tmp
5. -XX:MaxPermSize=2048m -XX:PermSize=512m
-XX:PermSize=64M JVM初始分配的非堆内存
-XX:MaxPermSize=128M JVM最大允许分配的非堆内存,按需分配
6. -Dspark.yarn.app.container.log.dir
设置容器 日志目录 为 /home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000001
7. org.apache.spark.deploy.yarn.ApplicationMaster
Java 程序入口类
8. –class
指定spark任务需要执行任务主类 org.apache.spark.ml.alogrithm.SmartRules
9. –jar
指定spark需要的jar包路径 hdfs://slave131:9000/user/mls_zl/lib2/cmpt/xxxxx-workflow-component-0.3.2-20180320-1101.jar
10. –arg
指定spark任务(客户端编写的代码)所需的参数
'hdfs://slave131:9000/user/mls_3.5/proc/1/11/92/submit_SmartRules_37Client.json'
11. –properties-file
/home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000001/__spark_conf__/__spark_conf__.properties
2.3 进程三
使用 bash -c 启动 executor 守护进程 即进程四
1 | hadoop 111013 111010 0 13:40 ? 00:00:00 /bin/bash -c ./jdk-8u161-linux-x64.tar.gz/jdk1.8.0_161/bin/java -server -Xmx4096m -Djava.io.tmpdir=/home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000002/tmp '-Dspark.ui.port=0' '-Dspark.driver.port=37011' -Dspark.yarn.app.container.log.dir=/home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000002 -XX:OnOutOfMemoryError='kill %p' org.apache.spark.executor.CoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@10.100.1.131:37011 --executor-id 1 --hostname slave131 --cores 8 --app-id application_1519271509270_0745 --user-class-path file:/home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000002/__app__.jar 1>/home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000002/stdout 2>/home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000002/stderr |
2.4 进程四:CoarseGrainedExecutorBackend
在spark中,executor是负责计算任务的,而CoarseGrainedExecutorBackend 则是负责Executor对象的创建和维护的
1 | hadoop 111567 111013 99 13:40 ? 00:00:32 ./jdk-8u161-linux-x64.tar.gz/jdk1.8.0_161/bin/java -server -Xmx4096m -Djava.io.tmpdir=/home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000002/tmp -Dspark.ui.port=0 -Dspark.driver.port=37011 -Dspark.yarn.app.container.log.dir=/home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000002 -XX:OnOutOfMemoryError=kill %p org.apache.spark.executor.CoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@10.100.1.131:37011 --executor-id 1 --hostname slave131 --cores 8 --app-id application_1519271509270_0745 --user-class-path file:/home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000002/__app__.jar |
1. -Dspark.ui.port
0 代表随机选择一个可用的端口
2. -Dspark.driver.port
驱动器监听端口号 37011
3. -Dspark.yarn.app.container.log.dir
指定app.container 的日志位置:/home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000002
4. -XX:OnOutOfMemoryError=kill %p
出现OutOfMemoryError 时,启动 运行kill命令
5. org.apache.spark.executor.CoarseGrainedExecutorBackend
java 命令 主类
6. –driver-url
spark://CoarseGrainedScheduler@10.100.1.131:37011
指定CoarseGrainedScheduler对外暴露的url
7. –executor-id
执行器的id,1
8. –hostname
主机名 slave131,谁的主机名,待查?
9. –cores 8
执行核心数
10. –app-id
应用的id application_1519271509270_0745
由时间戳加id组成。
–user-class-path
file:/home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000002/__app__.jar
2.5 进程五
使用 bash -c 启动 进程五
1 | hadoop 111619 111616 0 13:40 ? 00:00:00 /bin/bash -c ./jdk-8u161-linux-x64.tar.gz/jdk1.8.0_161/bin/java -server -Xmx4096m -Djava.io.tmpdir=/home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000003/tmp '-Dspark.ui.port=0' '-Dspark.driver.port=37011' -Dspark.yarn.app.container.log.dir=/home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000003 -XX:OnOutOfMemoryError='kill %p' org.apache.spark.executor.CoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@10.100.1.131:37011 --executor-id 2 --hostname slave131 --cores 8 --app-id application_1519271509270_0745 --user-class-path file:/home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000003/__app__.jar 1>/home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000003/stdout 2>/home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000003/stderr |
2.6 进程六:CoarseGrainedExecutorBackend
1 | hadoop 112178 111619 99 13:40 ? 00:00:50 ./jdk-8u161-linux-x64.tar.gz/jdk1.8.0_161/bin/java -server -Xmx4096m -Djava.io.tmpdir=/home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000003/tmp -Dspark.ui.port=0 -Dspark.driver.port=37011 -Dspark.yarn.app.container.log.dir=/home/hadoop/hadoop-2.7.3/logs/userlogs/application_1519271509270_0745/container_1519271509270_0745_01_000003 -XX:OnOutOfMemoryError=kill %p org.apache.spark.executor.CoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@10.100.1.131:37011 --executor-id 2 --hostname slave131 --cores 8 --app-id application_1519271509270_0745 --user-class-path file:/home/hadoop/tmp/nm-local-dir/usercache/xxxxx/appcache/application_1519271509270_0745/container_1519271509270_0745_01_000003/__app__.jar |
三、总结
从上面的结果分析,提交某任务后,spark 启动的3个进程:一个 ApplicationMaster、两个CoarseGrainedExecutorBackend。
spark8-executor执行task比返回结果
概要
本篇博客是Spark 任务调度概述详细流程中的最后一部分,介绍Executor执行task并返回result给Driver。
receive task
上一篇博客Spark 任务调度之Driver send Task,最后讲到Executor接收Task,如下
1 | case LaunchTask(data) => |
Executor的launchTask方法将收到的信息封装为TaskRunner对象,TaskRunner继承自Runnable,Executor使用线程池threadPool调度TaskRunner,如下
1 | def launchTask(context: ExecutorBackend, taskDescription: TaskDescription): Unit = { |
接下来查看TaskRunner中run方法对应的逻辑,我将其分为deserialize task、run task、sendback result三部分。
deserialize task
1 | override def run(): Unit = { |
如上图注释,反序列化得到Task对象。
run task
1 | val value = try { |
如上图注释,调用Task的run方法执行计算,Task是抽象类,其实现类有两个,ShuffleMapTask和ResultTask,分别对应shuffle和非shuffle任务。
Task的run方法调用其runTask方法执行task,我们以Task的子类ResultTask为例(ShuffleMapTask相比ResultTask多了一个步骤,使用ShuffleWriter将结果写到本地),如下
为了说明上图中的func,我们以RDD的map方法为例,如下
至此,task的计算就完成了,task的run方法返回计算结果。
sendback result

如上图注释,对计算结果进行序列化,再根据其大小采取相应方式处理,最后调用CoarseGrainedExecutorBackend的statusUpdate方法返回result给Driver。
总结
从
- 上图①所示路径,执行task任务。
- 上图②所示路径,将执行结果返回给Driver,后续Driver调用TaskScheduler处理返回结果,不再介绍。
spark7-driver提交task
概要
本篇博客是Spark 任务调度概述详细流程中的第七部分,介绍Driver发送task到Executor的过程。
执行用户编写代码
Spark 任务调度之Register App中介绍了Driver中初始化SparkContext对象及注册APP的流程,SparkContext初始化完毕后,执行用户编写代码,仍以SparkPi为例,如下
1 | object SparkPi { |
如上图,SparkPi中调用RDD的reduce,reduce中
调用SparkContext.runJob方法提交任务,SparkContext.runJob方法调用DAGScheduler.runJob方法,如下
1 | def reduce(f: (T, T) => T): T = withScope { |
1 | def runJob[T, U: ClassTag]( |
DAGScheduler生成task
DAGScheduler中,根据rdd的Dependency生成stage,stage分为ShuffleMapStage和ResultStage两种类型,根据stage类型生成对应的task,分别是ShuffleMapTask、ResultTask,最后调用TaskScheduler提交任务
TaskScheduler提交task
TaskScheduler中使用TaskSetManager管理TaskSet,submitTasks方法最终调用CoarseGrainedSchedulerBackend的launchTasks方法将task发送到Executor,如下
1 | private def launchTasks(tasks: Seq[Seq[TaskDescription]]) { |
executorDataMap中保存了Executor的连接方式,关于Executor如何注册到executorDataMap中,参考Spark 任务调度之创建Executor。
Executor接收Task
Worker节点的CoarseGrainedExecutorBackend进程接收Driver发送的task,交给Executor对象处理,如下
1 | case LaunchTask(data) => |
Executor的创建过程请参考Spark 任务调度之创建Executor。
至此从RDD的action开始,至Executor对象接收任务的流程就结束了。
总结
介绍了从RDD的action开始,到Executor接收到task的流程,其中省略了DAG相关的部分,后续单独介绍,整理流程大致如下

spark6-创建executor 过程
spark 创建executor 过程
[TOC]
一、uml 图
下面的简单过程是
- CoarseGrainedExecutorBackend 介绍Executor 给Drive
- Drive注册完成Executor
- CoarseGrainedExecutorBackend 创建Executor
注: Drive 在类CoarseGrainedSchedulerBackend.scala中

二、Executor
Executor运行在Worker节点,主要负责执行task和cache数据。
2.1 Executor 类图
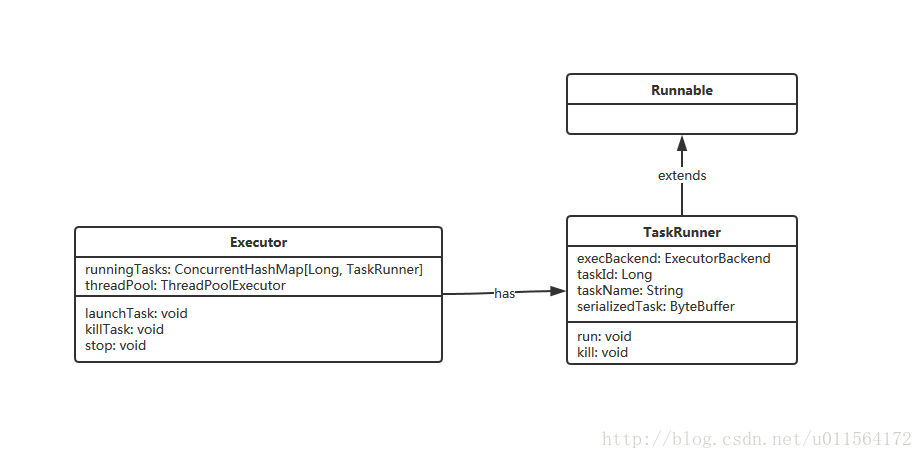
介绍TaskRunner和Executor的主要作用
- TaskRunner: 运行期Executor收到Driver发送的task信息,将其封装为TaskRunner,同时,TaskRunner继承Runnable,Executor使用线程池threadpool调度TaskRunner。
- Executor: 有两个重要属性,runningTasks和threadPool,分别用于维护正在运行的TaskRunner和调度TaskRunner线程。将收到的task信息封装为TaskRunner及执行TaskRunner的行为发生在Executor的launchTask方法中。
1 | def launchTask(context: ExecutorBackend, taskDescription: TaskDescription): Unit = { |
三、创建Executor过程
在启动 CoarseGrainedExecutorBackend 进程后,CoarseGrainedExecutorBackend会将自己注册到RpcEnv中,注册之后会调用CoarseGrainedExecutorBackend的onStart方法,该方法会向Driver发送RegisterExecutor消息。
CoarseGrainedExecutorBackend.scala
1 | override def onStart() { |
查看Driver对该消息的处理(CoarseGrainedSchedulerBackend.scala),Driver中先修改Executor信息有关的集合和变量,即注册Executor到Driver,Driver使用executorDataMap集合保存Executor信息。然后返回消息RegisteredExecutor给CoarseGrainedExecutorBackend。
CoarseGrainedSchedulerBackend.scala
1 | class DriverEndpoint(override val rpcEnv: RpcEnv, sparkProperties: Seq[(String, String)]) |
查看CoarseGrainedExecutorBackend中对RegisteredExecutor消息的处理 ,CoarseGrainedExecutorBackend创建了Executor对象,创建完毕的Executord对象此后用于执行Driver发送的task。
CoarseGrainedExecutorBackend.scala
1 | override def receive: PartialFunction[Any, Unit] = { |
spark5-启动CoarseGrainedExecutorBackend进程
启动CoarseGrainedExecutorBackend进程
Executor负责计算任务,即执行task,而Executor对象的创建及维护是由CoarseGrainedExecutorBackend负责的,CoarseGrainedExecutorBackend在spark运行期是一个单独的进程.
##一、CoarseGrainedExecutorBackend类
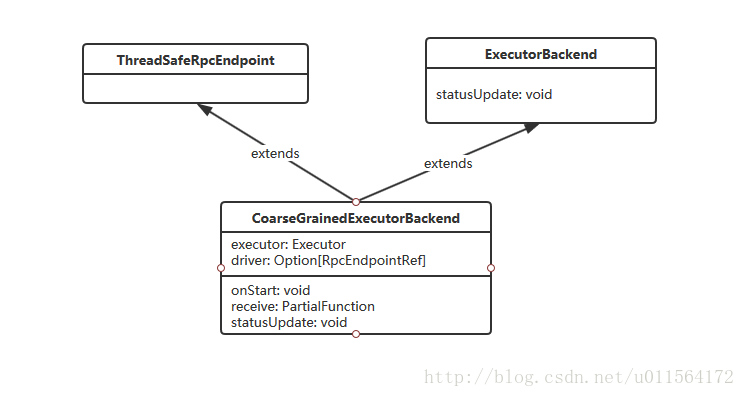
CoarseGrainedExecutorBackend是RpcEndpoint的子类,能够和Driver进行RPC通信。CoarseGrainedExecutorBackend维护了两个属性executor和driver,executor负责运行task,driver负责和Driver通信。- ExecutorBackend有抽象方法statusUpdate,负责将Executor的计算结果返回给Driver。
最后,CoarseGrainedExecutorBackend是spark运行期的一个进程,Executor运行在该进程内。
二、启动过程
2.1 uml

2.2 详细过程
在Worker进程收到LauncherExecutor消息后,Worker 会将消息封装为ExecutorRunner对象,调用其start方法。
1 | override def receive: PartialFunction[Any, Unit] = synchronized { |
start方法启动线程,调用ExecutorRunner的fetchAndRunExecutor方法,
1 | private[worker] def start() { |
fetchAndRunExecutor方法中将收到的信息拼接为Linux命令,然后使用ProcessBuilder执行Linux命令启动CoarseGrainedExecutorBackend
1 | private def fetchAndRunExecutor() { |
ProcessBuilder执行的Linux命令大致如下
1 | ./jdk-8u161-linux-x64.tar.gz/jdk1.8.0_161/bin/java |
java命令会调用CoarseGrainedExecutorBackend的main方法,main方法中处理命令行传入的参数,将参赛传给run方法,然后run方法中创建RpcEnv,并注册CoarseGrainedExecutorBackend
1 | private def run( |
参考
spark4-启动Executor
启动Executor
一、回顾
在《1、提交driver》已经介绍过,org.apache.spark.deploy.master.Master 的 receiveAndReply方法接收Client发送的消息RequestSubmitDriver。
前面已经介绍了schedule()中launchDriver的流程,即《2、启动driver》。
1 | override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = { |
本篇继续介绍schedule()方法另一个部分,Launch Executor
1 | private def schedule(): Unit = { |
二、启动Executor前的准备
查看startExecutorsOnWorkers方法
1 | private def startExecutorsOnWorkers(): Unit = { |
如上图注释,waitingApps信息主要是我们通过命令行传入的core和memory信息,startExecutorsOnWorkers方法的职责是调度waitingApps,即将core和memory分配到具体的Worker,Spark 任务调度之Register App介绍了Driver注册app的流程。
scheduleExecutorsOnWorkers方法中,可以使用spreadOutApps算法分配资源,即Executor分布在尽可能多的Worker节点上,相反,也支持Executor聚集在某些Worker节点上,通过参数spark.deploy.spreadOut配置,默认为true,如下
1 | private val spreadOutApps = conf.getBoolean("spark.deploy.spreadOut", true) |
三、Launch Executor
startExecutorsOnWorkers方法中,最后调用allocateWorkerResourceToExecutors方法,如下
1 | private def allocateWorkerResourceToExecutors( |
上图最后处调用launchExecutor方法,如下
1 | private def launchExecutor(worker: WorkerInfo, exec: ExecutorDesc): Unit = { |
如上图注释,给Worker节点发送LaunchExecutor消息,Worker节点收到消息,Launch Executor部分就结束了,下一部分具体讲Executor在Worker节点的启动,最后,Worker接收LaunchExecutor消息对应代码如下:
1 | case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) => |
总结
介绍Master节点Launch Executor的过程,分两步
- schedule waitingApps
- launch Executor
流程如下

spark3-启动用户编写的App
启动用户编写的App
上一篇讲到了Worker进程使用java.lang.ProcessBuilder执行java -cp命令启动用户编写的程序。
1 | java -cp $SPARK_ASSEMBLY_JAR \ |
通过 DriverWrapper 来启动 用户编写的应用程序(本文为sparkPi程序):
1 | object DriverWrapper { |
SparkPi程序
SparkPi程序 代码如下:
1 | import scala.math.random |
SparkContext初始化
该类全类名 org.apache.spark.SparkContext。下面的SparkContext初始化的主要代码过程。
1 | class SparkContext(config: SparkConf) extends Logging { |
TaskScheduler的创建与启动
上文中有这一段代码,在该章节详细讲解。
该小节仅简单介绍了AppClient的注册,详细信息见下一小节。
1 | val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode) |
TaskScheduler的创建
全路径 org.apache.spark.SparkContext 下的 createTaskScheduler 方法
TaskSchedulerImpl: 继承自TaskScheduler
- 作用在Driver中: 将DAGScheduler生成的task,使用SchedulerBackend和DriverEndpoint发送给Executor。
1 | // 返回 SchedulerBackend, TaskScheduler |
TaskScheduler的初始化:
全路径 org.apache.spark.scheduler.TaskSchedulerImpl
1 | def initialize(backend: SchedulerBackend) { |
TaskScheduler的启动
全路径 org.apache.spark.scheduler.TaskSchedulerImpl 下的 start 方法
1 | override def start() { |
StandaloneSchedulerBackend:
- 调用父类CoarseGrainedSchedulerBackend的start方法创建DriverEndPoint
- 创建 AppClient 并向 Master 注册。
1 | override def start() { |
AppClient的注册
本小节接着 如下代码讲解:
全路劲 org.apache.spark.scheduler.cluster.StandaloneSchedulerBackend
1 | override def start() { |
ClientEndpoint.onStart() 方法
1 | override def onStart(): Unit = { |
Master 接收消息:
全路径 org.apache.spark.deploy.master.Master
1 | override def receive: PartialFunction[Any, Unit] = { |
总结
最后,完整流程如下 。
注:图中的 SparkDeploySchedulerBackend 应该为 StandaloneSchedulerBackend。
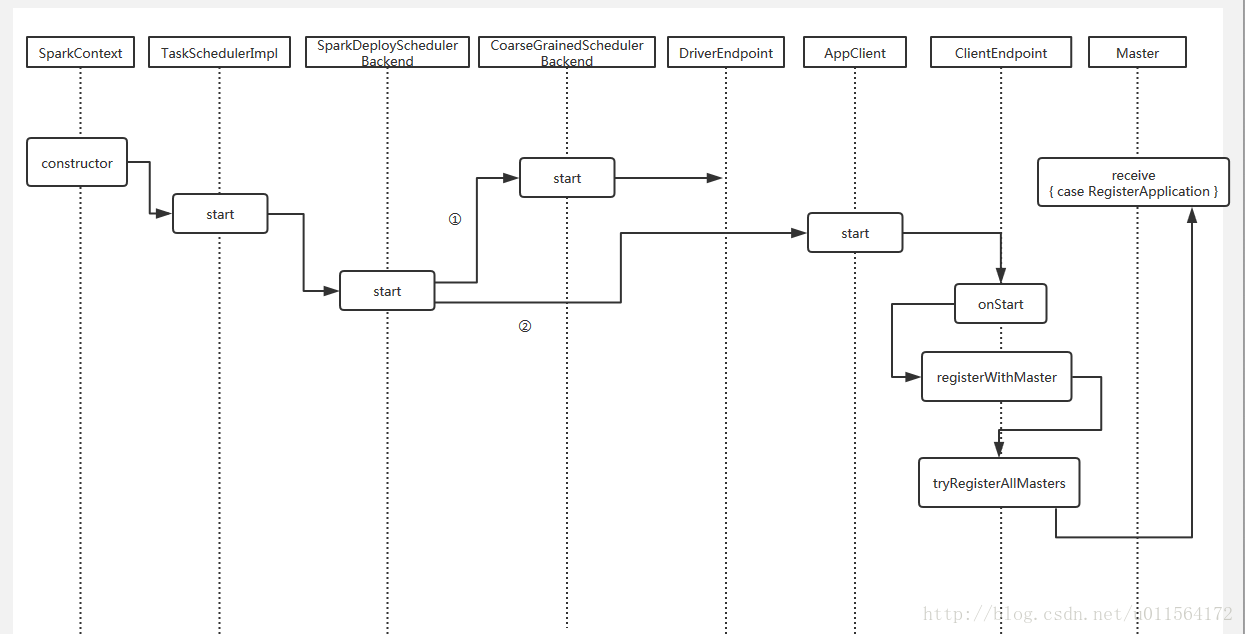
注释:
①,Driver端注册DriverEndpoint到RpcEnv的流程,之后DriverEndpoint用于和Executor通信,包括send task和接收返回的计算结果。
②,Driver向Master注册APP的流程。