spring websocket 配置样例
1 |
|
1 |
|
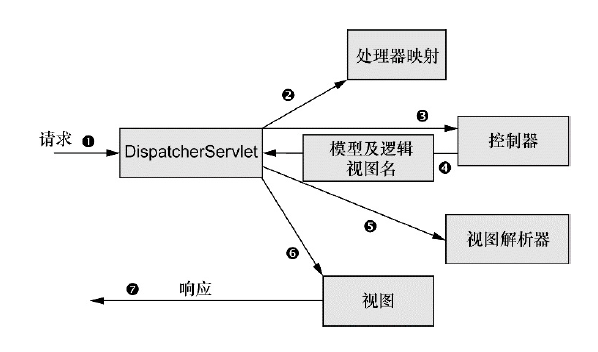
请求离开浏览器,携带用户请求的信息前往 DispatcherServlet
DispatcherServlet 是一个前端控制器,任务是将请求发送给指定的 controller 方法。
因此 DispatcherServlet 需要通过查询 处理器映射 来确定请求的下一站是什么。
通过 处理器映射 确定好目的地后,DispatcherServlet 会将请求发送给指定的控制器
控制器在完成逻辑处理后,通常会产生一些信息(model)。之后,将 产生的model 和 指定的视图名 一起发回给 DispatcherServlet。
DispatcherServlet 通过视图解析器(view resolver)将 逻辑视图名 匹配为一个特定的视图实现。
DispatcherServlet 将模型数据交付给视图,渲染出最后的结果。
通过响应对象将 最终的渲染结果传递到客户端。
详见 《spring实战》章节5.1.2
即面向切面编程,横切关注点分离和织入。可以用于日志、事务处理权限控制等。
单独使用时: 作用于类名,指定该类属于哪一个profile环境
与@bean一起: 作用于方法,指定该bean属于哪一个profile环境
设置 属性 spring.profiles.active。
@Conditional 注解: 作用于类名上,与 Condition接口 配合。Condition 接口: 只有一个 matches方法,只有在该方法返回 true 时才会创建带有@Conditional的bean。
通过这两个注解和接口的配合,可以下面措施来决定是否创建 被注解的bean。
样例 Profile
1 | ({ElementType.TYPE, ElementType.METHOD}) |
##自动装配歧义性
@Primary, 与@bean或者@Component组合: 将有该注解的bean设为首选项@Qualifier, 与@Autowired组合: 指定注入哪个bean@Qualifier, 与@Component或@Bean组合: 指定该bean生产的beanId##bean的作用域
@Scope注解 与@Component或@Bean组合,表明bean的作用域。
其有以下四种值:
请求域和会话域的详细介绍 参见《spring实战》章节3.4.1 。
1 | public class Ad{ |
属性占位符需要放到 “${ … }”之中
SpEL表达式需要放到 “#{ … }”中
例子
1 | -- 调用普通类的方法 |
@Component 放在类名上: 表明该类为 一个spring 组件类。@ComponentScan 放在类名上: 开启扫描功能, spring 会去扫描指定 包名 或者 类名 的 java 配置类。@Autowired 放在字段或者方法上: 从应用上下文中,找到符合条件的类实例A,将该实例A与被注解的变量绑定。当引用第三方jar时,是无法在需要的类上加 @Component 注解的,因此 需要使用另一种方法: 配置类。
@Configuration 放在类名上: 表明该类为配置类,该类包含各种 bean 实例@Bean 放在方法上: 表明 该方法的返回对象 为一个 bean 实例,该实例会被注册到spring应用上下文中。@Import 放在类名上: 将 @Import 的 value属性指定的普通类或者配置类加载到当前应用上下文中。需要注意的是 当调用 @Bean 注解的方法,spring会拦截该方法的调用,返回该方法创建的bean,而不是创建新的对象。
由于通过注解形式基本能代替xml方式。这里就不介绍了。
使 相互协作的类 保持松散耦合。
允许开发者将 遍布应用各处的功能 统一分离出来,整合成可重用的类。如 日志、事务管理和安全等服务
通过封装 jdbc 等 样板代码,利用 JdbcTemplate 等 减少 样板代码的重复量。
spring的bean是由spring的容器管理的。
spring的容器主要分为两大类:
最基本的 ApplicationContext 接口
最基本的 beanFactory 接口
下面主要介绍 应用上下文。
该类用于 装载bean 的定义并将他们组装起来。
spring应用上下文有多种实现:
WebApplicationContext 后缀的应用上下文,主要用于Web应用。会在之后详细讲解。
具体介绍 阅读 <<spring实战>>。
数据库级别
select * from nls_database_parameters;
会话级别
select * from nls_session_parameters;
select * from v$version;
SELECT userenv(‘language’) FROM dual;
alter session set nls_sort = SCHINESE_PINYIN_M;
select * from dept order by nlssort(name,’NLS_SORT=SCHINESE_PINYIN_M’);
set NLS_SORT=SCHINESE_PINYIN_M ;
-Duser.language=zh -Duser.region=CN -Duser.country=CN
NLS_SORT 定义了 order by 语句的整理顺序:
BINARY sort,则 order by排序基于 字符的numeric value顺序来进行排序(binary排序要求更少的系统负载)linguistic sort,order by排序基于 字符的linguistic sort定义的排序顺序。(Most (but not all) languages supported by the NLS_LANGUAGE parameter also support a linguistic sort with the same name.)NLS_SORT 的默认值是由 NLS_LANGUAGE 决定的。
索引是根据binary order key排序的。
当将 NLS_SORT 设置为非 BINARY SORT 时: 优化器会在执行计划中,进行全表扫描和全排序操作。
当将 NLS_SORT 设置为 BINARY SORT时: 优化器可以使用索引来进行 order by 排序。
若想建立 按拼音排序的索引: 可以建立 linguistic index
CREATE INDEX nls_index ON my_table (NLSSORT(name, ‘NLS_SORT = SCHINESE_PINYIN_M’));
http://wuaner.iteye.com/blog/681614
https://blog.csdn.net/qincidong/article/details/8998284
https://docs.oracle.com/cd/B19306_01/server.102/b14225/ch3globenv.htm#NLSPG003
https://docs.oracle.com/cd/B19306_01/server.102/b14225/applocaledata.htm
https://www.oracle.com/technetwork/testcontent/sort-083215.html
tomcat的优化。
kafka 是一个分布式流媒体系统(streaming platform)。