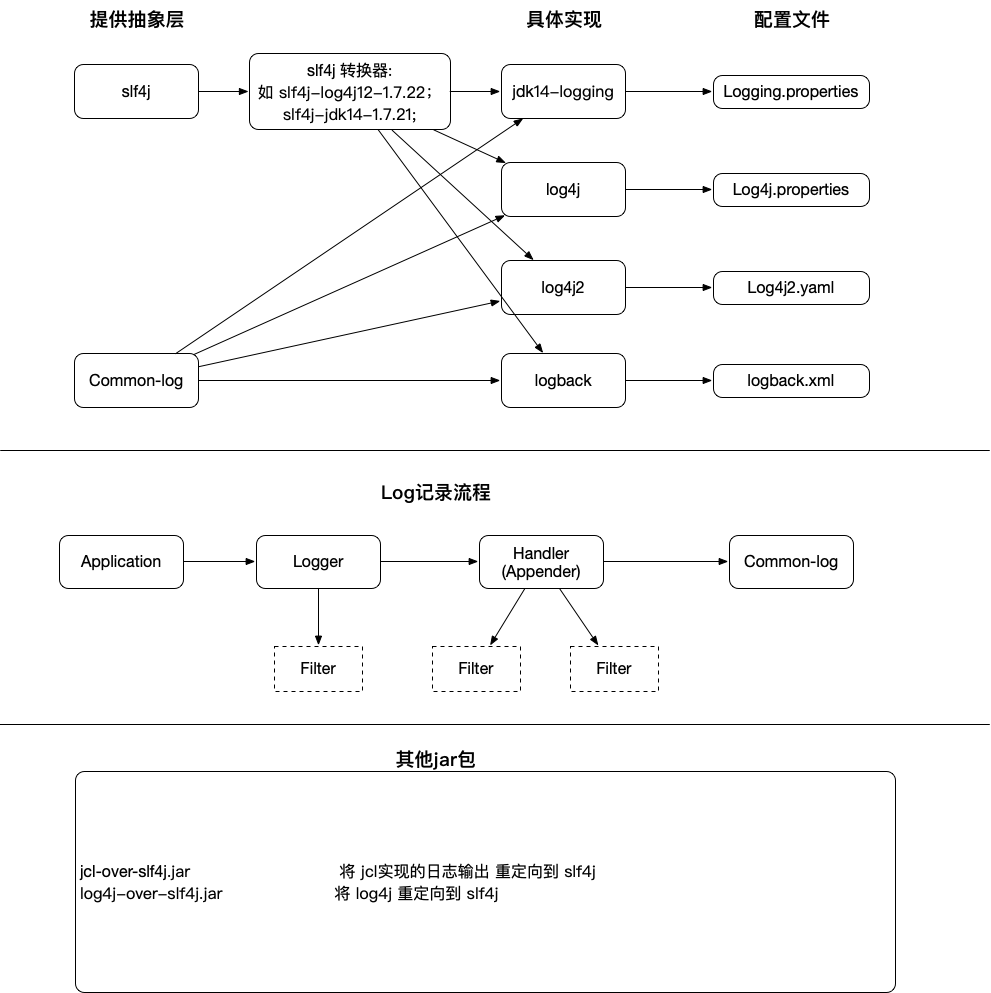
使用java代码 获取 TGT
1 | public void login(Configuration conf) throws IOException { |
1 | /* |
1 | public synchronized |
Krb5LoginModule 中几个重要的方法:
- attemptAuthentication()
- login()
- commit()
HadoopLoginModule中几个重要的方法:
- login()
- commit()
文章收集
UserGroupInformation.doAs
https://blog.csdn.net/weixin_35852328/article/details/83620379
Hadoop安全认证(2)
https://blog.csdn.net/daiyutage/article/details/52091779
Should I call ugi.checkTGTAndReloginFromKeytab() before every action on hadoop?
Hadoop Delegation Tokens详解【译文】
https://www.jianshu.com/p/617fa722e057
MIT 官方文档