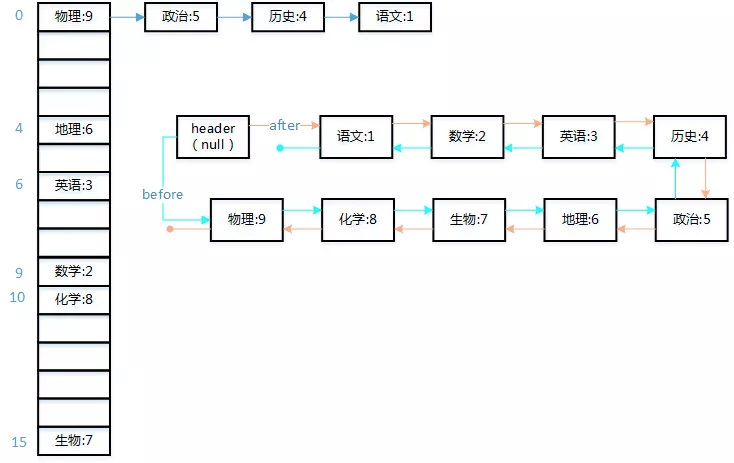
LinkedHashMap 也是一个HashMap,但是内部额外维持了一个双向链表,保存了记录的插入顺序。本文源代码参考值jdk1.8
LinkedHashMap,见名知义,带链表的 HashMap, 所以LinkedHashMap是有序,LinkedHashMap作为HashMap的扩展,它改变了HashMap无序的特征。
数据结构
LinkedHashMap 改造了 HashMap.Node<K,V> ,添加了两个 Entry<K,V>,用于记录插入顺序,before 和 after是构成双向链表的关键。
1 2 3 4 5 6 static class Entry <K ,V > extends HashMap .Node <K ,V > Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super (hash, key, value, next); } }
重要参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 transient LinkedHashMap.Entry<K,V> head;transient LinkedHashMap.Entry<K,V> tail;final boolean accessOrder;
重要方法 构造方法 LinkedHashMap的构造方法,都是通过调用父类的构造方法来实现,大部分accessOrder默认为false
accessOrder: false按插入顺序排序,true访问顺序排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public LinkedHashMap (int initialCapacity, float loadFactor) super (initialCapacity, loadFactor); accessOrder = false ; } public LinkedHashMap (int initialCapacity) super (initialCapacity); accessOrder = false ; } public LinkedHashMap () super (); accessOrder = false ; } public LinkedHashMap (Map<? extends K, ? extends V> m) super (m); accessOrder = false ; } public LinkedHashMap (int initialCapacity, float loadFactor, boolean accessOrder) super (initialCapacity, loadFactor); this .accessOrder = accessOrder; }
put 方法 LinkedHashMap并没有重写任何put方法。但是其重写了与其相关的 newNode()、afterNodeAccess()、 afterNodeInsertion().
newNode() 在新建 LinkedHashMap.Entry<K,V> 之后,将新建的 Entry 连接到双向链表的最后。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Node<K,V> newNode (int hash, K key, V value, Node<K,V> e) { LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e); linkNodeLast(p); return p; } private void linkNodeLast (LinkedHashMap.Entry<K,V> p) LinkedHashMap.Entry<K,V> last = tail; tail = p; if (last == null ) head = p; else { p.before = last; last.after = p; } }
afterNodeAccess() 在 accessOrder为 true的情况下:
在访问后,将访问的节点调整到双向链表的尾部
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void afterNodeAccess (Node<K,V> e) LinkedHashMap.Entry<K,V> last; if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null ; if (b == null ) head = a; else b.after = a; if (a != null ) a.before = b; else last = b; if (last == null ) head = p; else { p.before = last; last.after = p; } tail = p; ++modCount; } }
afterNodeInsertion() afterNodeInsertion方法是在哈希表中插入了一个新节点时调用的,它会把链表的头节点删除掉,删除的方式是通过调用HashMap的removeNode方法。
afterNodeInsertion方法一般是不生效的。但是如果需要用到 LRU 算法,则可以重写removeEldestEntry方法。LRU算法暂时没有研究。
1 2 3 4 5 6 7 8 9 10 11 12 void afterNodeInsertion (boolean evict) LinkedHashMap.Entry<K,V> first; if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null , false , true ); } } protected boolean removeEldestEntry (Map.Entry<K,V> eldest) return false ; }
remove 方法 LinkedHashMap同样没有重写remove方法.仅仅重写了afterNodeRemoval()
afterNodeRemoval() 这个方法是当HashMap删除一个键值对时调用的,它会把在HashMap中删除的那个键值对一并从链表中删除,保证了哈希表和链表的一致性。
1 2 3 4 5 6 7 8 9 10 11 12 13 void afterNodeRemoval (Node<K,V> e) LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.before = p.after = null ; if (b == null ) head = a; else b.after = a; if (a == null ) tail = b; else a.before = b; }
get方法 获取对应的 value 时,若 accessOrder为 true,则执行afterNodeAccess方法
1 2 3 4 5 6 7 8 public V get (Object key) Node<K,V> e; if ((e = getNode(hash(key), key)) == null ) return null ; if (accessOrder) afterNodeAccess(e); return e.value; }
遍历 重写 entrySet()
1 2 3 4 5 6 7 8 9 10 public Set<Map.Entry<K,V>> entrySet() { Set<Map.Entry<K,V>> es; return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es; } final class LinkedEntrySet extends AbstractSet <Map .Entry <K ,V >> public final Iterator<Map.Entry<K,V>> iterator() { return new LinkedEntryIterator(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 final class LinkedEntryIterator extends LinkedHashIterator implements Iterator <Map .Entry <K ,V >> { public final Map.Entry<K,V> next () { return nextNode(); } } abstract class LinkedHashIterator LinkedHashMap.Entry<K,V> next; LinkedHashMap.Entry<K,V> current; int expectedModCount; LinkedHashIterator() { next = head; expectedModCount = modCount; current = null ; } public final boolean hasNext () return next != null ; } final LinkedHashMap.Entry<K,V> nextNode () { LinkedHashMap.Entry<K,V> e = next; if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (e == null ) throw new NoSuchElementException(); current = e; next = e.after; return e; } public final void remove () Node<K,V> p = current; if (p == null ) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException(); current = null ; K key = p.key; removeNode(hash(key), key, null , false , false ); expectedModCount = modCount; } }
该方法的实现可以看出,迭代LinkedHashMap,就是从内部维护的双链表的表头开始循环输出
获取第一个和最后一个元素 1 2 3 4 5 // 第一个元素: 程序执行一次即可找到 entrySet().iterator().next() // 最后一个元素: 遍历所有元素,获取最后一个。 while (iterator.hasNext()) { lastElement = iterator.next() }
来源 https://blog.csdn.net/zxt0601/article/details/77429150