启动CoarseGrainedExecutorBackend进程
Executor负责计算任务,即执行task,而Executor对象的创建及维护是由CoarseGrainedExecutorBackend负责的,CoarseGrainedExecutorBackend在spark运行期是一个单独的进程.
##一、CoarseGrainedExecutorBackend类
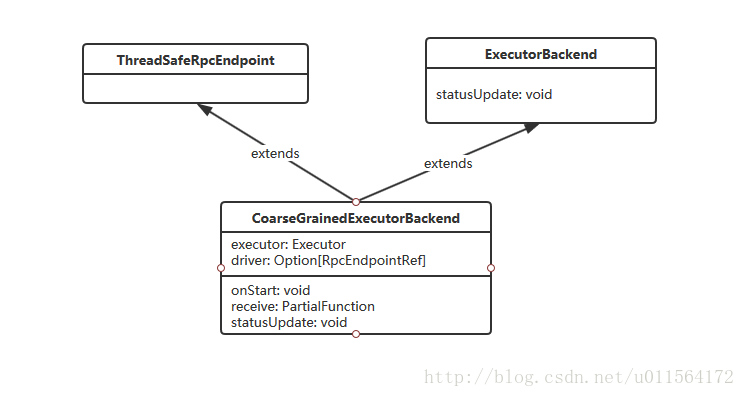
CoarseGrainedExecutorBackend是RpcEndpoint的子类,能够和Driver进行RPC通信。CoarseGrainedExecutorBackend维护了两个属性executor和driver,executor负责运行task,driver负责和Driver通信。- ExecutorBackend有抽象方法statusUpdate,负责将Executor的计算结果返回给Driver。
最后,CoarseGrainedExecutorBackend是spark运行期的一个进程,Executor运行在该进程内。
二、启动过程
2.1 uml

2.2 详细过程
在Worker进程收到LauncherExecutor消息后,Worker 会将消息封装为ExecutorRunner对象,调用其start方法。
1 | override def receive: PartialFunction[Any, Unit] = synchronized { |
start方法启动线程,调用ExecutorRunner的fetchAndRunExecutor方法,
1 | private[worker] def start() { |
fetchAndRunExecutor方法中将收到的信息拼接为Linux命令,然后使用ProcessBuilder执行Linux命令启动CoarseGrainedExecutorBackend
1 | private def fetchAndRunExecutor() { |
ProcessBuilder执行的Linux命令大致如下
1 | ./jdk-8u161-linux-x64.tar.gz/jdk1.8.0_161/bin/java |
java命令会调用CoarseGrainedExecutorBackend的main方法,main方法中处理命令行传入的参数,将参赛传给run方法,然后run方法中创建RpcEnv,并注册CoarseGrainedExecutorBackend
1 | private def run( |