objectDriverWrapper{ defmain(args: Array[String]) { args.toList match { case workerUrl :: userJar :: mainClass :: extraArgs => val conf = newSparkConf() val rpcEnv = RpcEnv.create("Driver", Utils.localHostName(), 0, conf, newSecurityManager(conf)) rpcEnv.setupEndpoint("workerWatcher", newWorkerWatcher(rpcEnv, workerUrl))
val currentLoader = Thread.currentThread.getContextClassLoader val userJarUrl = newFile(userJar).toURI().toURL() val loader = if (sys.props.getOrElse("spark.driver.userClassPathFirst", "false").toBoolean) { newChildFirstURLClassLoader(Array(userJarUrl), currentLoader) } else { newMutableURLClassLoader(Array(userJarUrl), currentLoader) } Thread.currentThread.setContextClassLoader(loader)
// Delegate to supplied main class val clazz = Utils.classForName(mainClass) val mainMethod = clazz.getMethod("main", classOf[Array[String]]) mainMethod.invoke(null, extraArgs.toArray[String])
/** Computes an approximation to pi */ objectSparkPi{ defmain(args: Array[String]) { if (args.length == 0) { System.err.println("Usage: SparkPi <master> [<slices>]") System.exit(1) } val spark = newSparkContext(args(0), "SparkPi", System.getenv("SPARK_HOME"), SparkContext.jarOfClass(this.getClass)) val slices = if (args.length > 1) args(1).toInt else2 val n = 100000 * slices val count = spark.parallelize(1 to n, slices).map { i => val x = random * 2 - 1 val y = random * 2 - 1 if (x*x + y*y < 1) 1else0 }.reduce(_ + _) println("Pi is roughly " + 4.0 * count / n) spark.stop() } }
classSparkContext(config: SparkConf) extendsLogging{ // 将所有参数整合,clone 出一个完整的SparkConf对象(SparkConf会加载所有的以"spark."开头的系统变量), // 然后用该SparkConf对象构造SparkContext private[spark] defthis( master: String, appName: String, sparkHome: String, jars: Seq[String]) = this(master, appName, sparkHome, jars, Map()) // SparkContext的初始化主要在 try 代码块中 try{ //校验逻辑和基本配置设置省略 // "_jobProgressListener" should be set up before creating SparkEnv because when creating // "SparkEnv", some messages will be posted to "listenerBus" and we should not miss them. _jobProgressListener = newJobProgressListener(_conf) listenerBus.addListener(jobProgressListener)
// 该env中包含 serializer, RpcEnv, block manager, map output tracker, etc _env = createSparkEnv(_conf, isLocal, listenerBus) // 所有线程能够通过 SparkEnv.get()获取相关信息 SparkEnv.set(_env) // If running the REPL, register the repl's output dir with the file server. _conf.getOption("spark.repl.class.outputDir").foreach { path => val replUri = _env.rpcEnv.fileServer.addDirectory("/classes", newFile(path)) _conf.set("spark.repl.class.uri", replUri) } //该类用于监控 job and stage progress _statusTracker = newSparkStatusTracker(this) _progressBar = if (_conf.getBoolean("spark.ui.showConsoleProgress", true) && !log.isInfoEnabled) { Some(newConsoleProgressBar(this)) } else { None } // 创建spark-Ui _ui = if (conf.getBoolean("spark.ui.enabled", true)) { Some(SparkUI.createLiveUI(this, _conf, listenerBus, _jobProgressListener, _env.securityManager, appName, startTime = startTime)) } else { // For tests, do not enable the UI None } // Bind the UI before starting the task scheduler to communicate // the bound port to the cluster manager properly _ui.foreach(_.bind())
// 创建executor分配管理器 val dynamicAllocationEnabled = Utils.isDynamicAllocationEnabled(_conf) _executorAllocationManager = if (dynamicAllocationEnabled) { schedulerBackend match { case b: ExecutorAllocationClient => Some(newExecutorAllocationManager( schedulerBackend.asInstanceOf[ExecutorAllocationClient], listenerBus, _conf)) case _ => None } } else { None } _executorAllocationManager.foreach(_.start())
// 创建 cleaner for RDD, shuffle, and broadcast state _cleaner = if (_conf.getBoolean("spark.cleaner.referenceTracking", true)) { Some(newContextCleaner(this)) } else { None } _cleaner.foreach(_.start()) //设置并启动监听总线ListenerBus setupAndStartListenerBus() //task scheduler准备完毕,更新SparkEnv和将SparkContext标记为激活 postEnvironmentUpdate() //发送应用启动时间 postApplicationStart()
// Post init _taskScheduler.postStartHook() //注册dagScheduler.metricsSource _env.metricsSystem.registerSource(_dagScheduler.metricsSource) //注册BlockManagerSource _env.metricsSystem.registerSource(newBlockManagerSource(_env.blockManager)) //注册executorAllocationManagerSource _executorAllocationManager.foreach { e => _env.metricsSystem.registerSource(e.executorAllocationManagerSource) }
// Make sure the context is stopped if the user forgets about it. This avoids leaving // unfinished event logs around after the JVM exits cleanly. It doesn't help if the JVM // is killed, though. logDebug("Adding shutdown hook") // force eager creation of logger _shutdownHookRef = ShutdownHookManager.addShutdownHook( ShutdownHookManager.SPARK_CONTEXT_SHUTDOWN_PRIORITY) { () => logInfo("Invoking stop() from shutdown hook") stop() } } catch { caseNonFatal(e) => logError("Error initializing SparkContext.", e) try { stop() } catch { caseNonFatal(inner) => logError("Error stopping SparkContext after init error.", inner) } finally { throw e } }
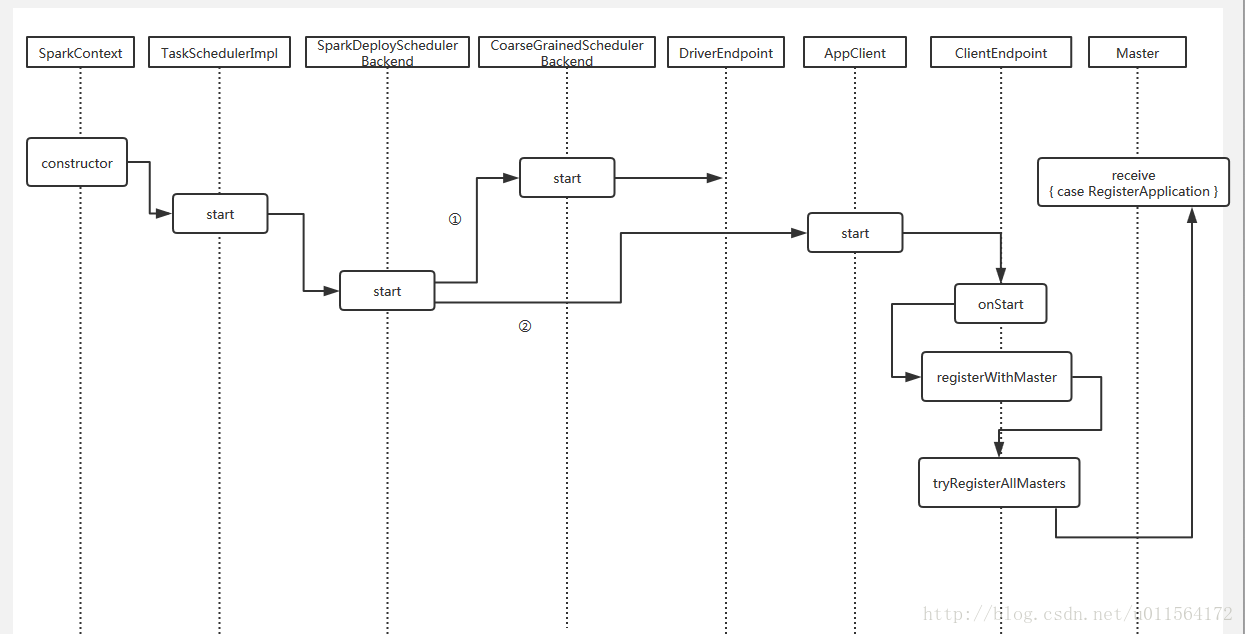
caseRegisterApplication(description, driver) => // TODO Prevent repeated registrations from some driver if (state == RecoveryState.STANDBY) { // ignore, don't send response } else { logInfo("Registering app " + description.name) // 创建 ApplicationInfo 实例 val app = createApplication(description, driver) // 注册 app registerApplication(app) logInfo("Registered app " + description.name + " with ID " + app.id) //PersistenceEngine作用 // - 当Master发生故障时,来读取持久化的Application,Worker,Driver的详细信息。 // - 负责写入持久化Application,Worker,Driver的详细信息。 persistenceEngine.addApplication(app) //向StandaloneAppClient发送消息RegisteredApplication,表示已注册Application driver.send(RegisteredApplication(app.id, self)) /** * Schedule the currently available resources among waiting apps. This method will be called * every time a new app joins or resource availability changes. */ schedule() } }
privatedefregisterApplication(app: ApplicationInfo): Unit = { val appAddress = app.driver.address if (addressToApp.contains(appAddress)) { logInfo("Attempted to re-register application at same address: " + appAddress) return }